Mixed-Design ANOVA Calculator
Free online split-plot (mixed) ANOVA for between-subjects and within-subjects factors. Computes F-statistics for both main effects and the interaction, with Greenhouse–Geisser and Huynh–Feldt sphericity corrections, partial eta squared, and APA-ready output.
📊 1. Enter Your Data
Each row below represents one between-subjects group (e.g., Treatment vs Control). Inside each group, enter the within-subjects measurements (e.g., Time 1, Time 2, Time 3) — one row of comma-separated values per subject, one subject per line. Group names are editable. Click + Add Group to add more between-subjects groups.
n_subjects × k_within_levels values stacked subject-by-subject (Subject 1 T1, Subject 1 T2, Subject 1 T3, Subject 2 T1, ...).
📐 5. Formulas & Technical Notes
A. Formulas (full)
Sums of Squares — Three-Way Partition
SS_total = Σ(Yijk − Ȳ...)² Between-Subjects partition SS_A = b·n · Σ_i (Ȳi.. − Ȳ...)² SS_S(A) = b · Σ_i Σ_k (Ȳi.k − Ȳi..)² ← subjects-within-groups (error 1) Within-Subjects partition SS_B = a·n · Σ_j (Ȳ.j. − Ȳ...)² SS_AB = n · Σ_i Σ_j (Ȳij. − Ȳi.. − Ȳ.j. + Ȳ...)² SS_B×S(A) = SS_total − SS_A − SS_S(A) − SS_B − SS_AB ← within-subjects error (error 2)
Degrees of Freedom
df_A = a − 1 (between groups) df_S(A) = a(n − 1) (subjects within groups) df_B = b − 1 (within-subjects levels) df_AB = (a − 1)(b − 1) (interaction) df_B×S(A) = a(n − 1)(b − 1) (within-subjects error)
F-Statistics
F_A = MS_A / MS_S(A) → tests Group main effect F_B = MS_B / MS_B×S(A) → tests within-subjects (Time) main effect F_AB = MS_AB / MS_B×S(A) → tests Group × Time interaction
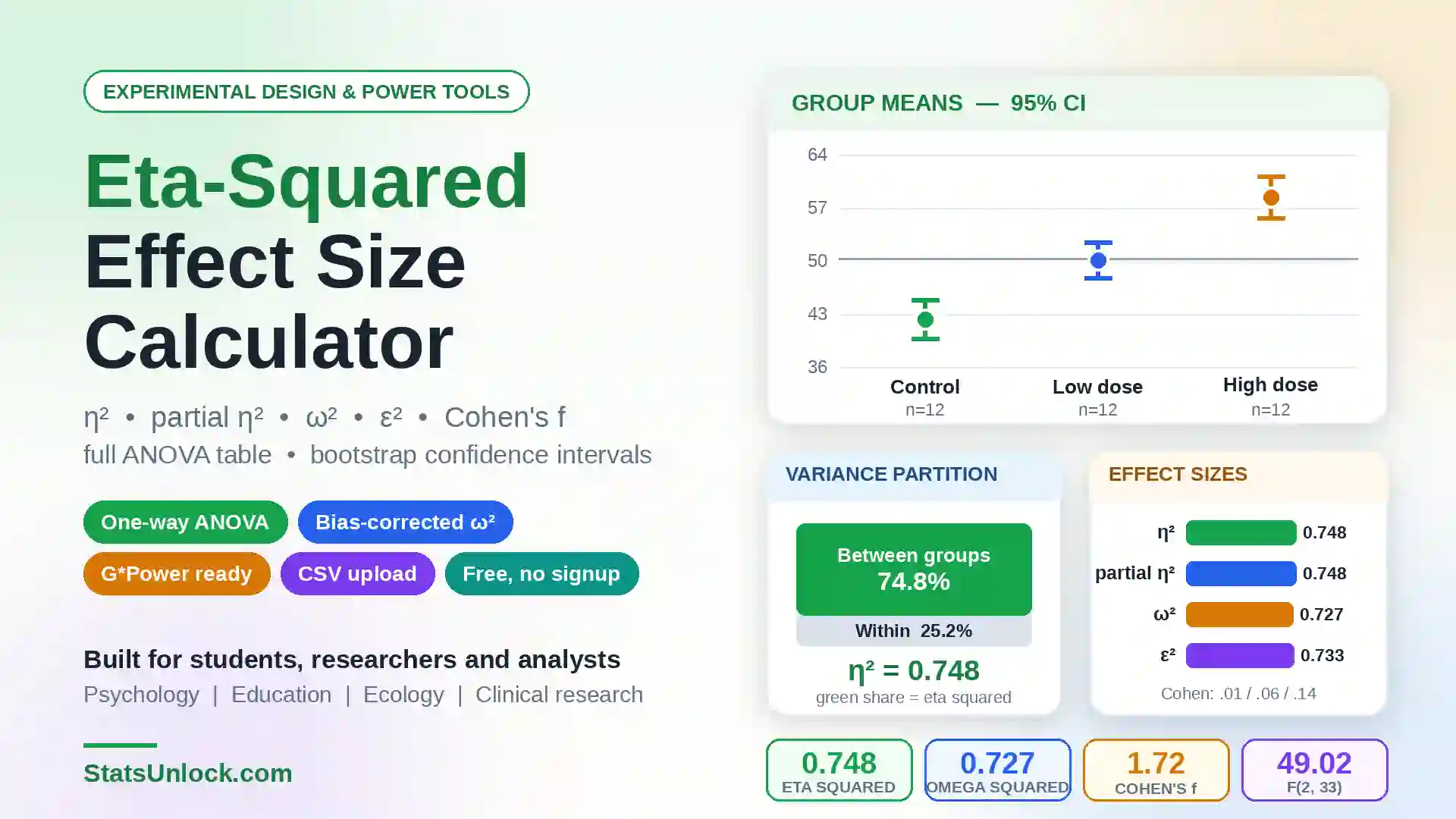
Effect Size — Partial Eta Squared
η²_p(A) = SS_A / (SS_A + SS_S(A)) η²_p(B) = SS_B / (SS_B + SS_B×S(A)) η²_p(AB) = SS_AB / (SS_AB + SS_B×S(A)) Benchmarks (Cohen, 1988): 0.01 small · 0.06 medium · 0.14 large
Sphericity Corrections
Greenhouse–Geisser ε̂ = (Σλi)² / [(b−1) · Σλi²] Huynh–Feldt ε̃ = min(1, n·(b−1)·ε̂ − 2) / [(b−1)·(n−1 − (b−1)·ε̂)] Corrected df: df1' = ε·df1 df2' = ε·df2 Where λi are the eigenvalues of the within-subjects covariance matrix.
Where:
a = number of between-subjects groups b = number of within-subjects levels n = subjects per group (assumed balanced) Yijk = score for subject k in group i at level j Ȳ... = grand mean Ȳi.. = mean of group i Ȳ.j. = mean of within-subjects level j Ȳij. = mean of cell (i, j) Ȳi.k = mean for subject k in group i across within levels SS = sum of squares MS = mean square = SS / df ε = sphericity epsilon (1 = perfect sphericity)
B. Assumptions & Diagnostic Notes
- Independence of observations between groups. Subjects in different between-subjects groups must be independent.
- Normality of residuals within each cell. Each combination of group × time should have approximately normally distributed scores. Robust to mild violations when group sizes are equal and n > 15.
- Homogeneity of between-subjects variances. Check with Levene's test or compare cell SDs. Largest/smallest SD ratio < 2 is acceptable.
- Sphericity (within-subjects). Tested by Mauchly's W when b ≥ 3. When violated, apply Greenhouse–Geisser or Huynh–Feldt corrections (both reported above).
- Balanced design preferred. Equal n per group simplifies the SS partition. This tool assumes balanced n.
- If assumptions fail: Consider linear mixed-effects models (R
lme4) or robust ANOVA (Wilcox WRS2 package).
🎯 6. When to Use a Mixed-Design ANOVA
Decision Checklist & Real-World Examples
This free mixed-design ANOVA tool is designed for studies that combine a between-subjects factor (independent groups) with a within-subjects factor (repeated measures on the same subjects). It is one of the most commonly used designs in clinical trials, education research, sports science, and experimental psychology.
Use this test when ALL of these are true:
- You have at least 2 independent groups (between-subjects factor)
- Each subject is measured 2 or more times on the same outcome (within-subjects factor)
- Your dependent variable is continuous (interval or ratio)
- You want to test both main effects and their interaction
- Sample is approximately balanced and residuals are roughly normal
- Don't use if all measurements are on the same single group → use Repeated-Measures ANOVA
- Don't use if groups are measured only once → use One-Way ANOVA
- Don't use if data are heavily skewed and n is small → use a nonparametric mixed model or linear mixed-effects model
Real-world examples
- Medical research. Three drug groups (Placebo, Drug A, Drug B) measured at Pre, Mid, and Post — does blood pressure change differently across drugs over time?
- Education. Traditional vs Flipped classroom measured Q1 → Q4 — do learning trajectories diverge?
- Sports science. Control vs HIIT training measured at Week 0, 4, and 8 — does HIIT improve sprint time faster than control?
- Psychology. CBT vs Mindfulness vs Waitlist measured Pre, Post, and Follow-up — which therapy produces the largest reduction in anxiety, and does that benefit persist?
Sample size guidance
For 80% power to detect a medium interaction effect (Cohen's f = 0.25) at α = 0.05, you typically need n ≈ 24 per group with 2 groups and 3 time points (≈ 48 total). For small interaction effects (f = 0.10), expect n ≥ 80 per group.
Decision tree
Two or more groups → measured once → One-Way / Two-Way ANOVA
One group → measured repeatedly → Repeated-Measures ANOVA
Multiple groups → measured repeatedly → Mixed-Design ANOVA (this tool)
Non-normal data, complex random effects → Linear Mixed-Effects Model (LMM)
📖 7. How to Use This Mixed-Design ANOVA Calculator
Step-by-Step Walkthrough
- Step 1 — Enter your data. Use the Type / Paste tab (default). Each group is one row; within each group, paste comma-separated values per subject, one subject per line. For three time points, each subject row should be exactly 3 numbers (e.g.,
52, 48, 55). - Step 2 — Edit group names. Click any group name field to rename it (e.g., from "Group 1" to "Placebo").
- Step 3 — Set within-subjects level names. Enter comma-separated labels matching the number of values per row (e.g.,
Pre, Mid, Post). - Step 4 — Pick a sample dataset (optional). Five built-in datasets pre-fill the form so you can see the tool in action.
- Step 5 — Configure alpha. 0.05 is standard. Use 0.01 for more conservative inference.
- Step 6 — Run analysis. Click the green button. Nothing runs automatically on page load.
- Step 7 — Read summary cards. Three F-tests are shown: Group, Time, and Group × Time. Color = significance.
- Step 8 — Inspect the full ANOVA table. Each row gives df, SS, MS, F, p, and partial η².
- Step 9 — Check four visualizations. Interaction plot, error-bar chart, individual trajectories, and box plots together give a complete picture.
- Step 10 — Export. Click Download Doc for a plain-text report or Download PDF for a print-ready PDF.
❓ 8. Frequently Asked Questions
Q1. What is a mixed-design ANOVA and when should I use it?
A mixed-design ANOVA (also called split-plot ANOVA) is used when your study has at least one between-subjects factor (different groups of people) and at least one within-subjects factor (repeated measures on each person). Use it when you want to test whether a treatment effect changes over time across different groups — e.g., does blood pressure change differently across three drug conditions when measured at pre, mid, and post-treatment.
Q2. What is the difference between mixed ANOVA and repeated-measures ANOVA?
A repeated-measures ANOVA has only within-subjects factors (one group measured multiple times). A mixed-design ANOVA adds a between-subjects factor (separate groups), so you can test main effects of group, time, and their interaction.
Q3. What is the interaction effect in a mixed ANOVA?
The interaction effect (Group × Time) tests whether the within-subjects effect differs across groups. A significant interaction means the pattern of change over time is not the same across groups, which is often the most important finding — it tells you that the treatment is doing something different in different groups.
Q4. What is sphericity and why does it matter?
Sphericity is the assumption that variances of the differences between all pairs of within-subjects conditions are equal. When sphericity is violated, F-tests become liberal (too many false positives). This tool reports Greenhouse–Geisser and Huynh–Feldt corrections automatically when the within-subjects factor has 3 or more levels.
Q5. How do I interpret partial eta squared in a mixed ANOVA?
Partial eta squared (η²_p) is the proportion of variance in the outcome explained by an effect, after partialling out other effects. Cohen's (1988) benchmarks: 0.01 = small, 0.06 = medium, 0.14 = large. A partial η² of 0.25 for an interaction is a large effect.
Q6. What are the assumptions of a mixed-design ANOVA?
Independence of observations between groups, normality of residuals within each cell, homogeneity of variance across between-subjects groups (Levene's test), and sphericity for the within-subjects factor. The test is robust to mild violations when sample sizes are equal across groups.
Q7. How large a sample do I need for a mixed-design ANOVA?
As a rule of thumb, aim for at least 15–20 participants per between-subjects group. For 80% power to detect a medium interaction effect (f = 0.25, α = 0.05) with 2 groups and 3 time points, you typically need n ≈ 24 per group (≈ 48 total).
Q8. What should I do if sphericity is violated?
Apply the Greenhouse–Geisser epsilon (more conservative) or Huynh–Feldt epsilon (less conservative when ε > 0.75) to adjust the degrees of freedom. Both corrections are shown automatically in this tool. As a rule of thumb, use Greenhouse–Geisser when ε ≤ 0.75 and Huynh–Feldt when ε > 0.75.
Q9. How do I report a mixed-design ANOVA in APA 7th edition format?
Report each effect with F(df1, df2) = value, p = value, partial η² = value. Example: "There was a significant Group × Time interaction, F(2, 36) = 6.42, p = .004, η²_p = .26." See Section 3 for five full APA, thesis, plain-language, abstract, and pre-registration templates.
Q10. Can I use this calculator for my published research or thesis?
This tool is designed for educational use, class assignments, and exploratory analysis. For published research, verify results with peer-reviewed software (R afex, SPSS GLM Repeated Measures, JASP). Cite as: STATS UNLOCK. (2025). Mixed-design ANOVA calculator. Retrieved from https://statsunlock.com.
📚 9. References
The following references support the statistical methods used in this mixed-design ANOVA calculator, covering partial eta squared effect sizes, sphericity correction, and best practices in hypothesis testing and APA-format reporting.
- Fisher, R. A. (1925). Statistical methods for research workers. Oliver and Boyd. https://psychclassics.yorku.ca/Fisher/Methods/
- Greenhouse, S. W., & Geisser, S. (1959). On methods in the analysis of profile data. Psychometrika, 24(2), 95–112. https://doi.org/10.1007/BF02289823
- Huynh, H., & Feldt, L. S. (1976). Estimation of the Box correction for degrees of freedom from sample data in randomized block and split-plot designs. Journal of Educational Statistics, 1(1), 69–82. https://doi.org/10.3102/10769986001001069
- Mauchly, J. W. (1940). Significance test for sphericity of a normal n-variate distribution. The Annals of Mathematical Statistics, 11(2), 204–209. https://doi.org/10.1214/aoms/1177731915
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates. https://doi.org/10.4324/9780203771587
- Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications. SAGE link
- Maxwell, S. E., & Delaney, H. D. (2004). Designing experiments and analyzing data: A model comparison perspective (2nd ed.). Lawrence Erlbaum Associates. https://doi.org/10.4324/9781410609243
- Howell, D. C. (2013). Statistical methods for psychology (8th ed.). Cengage Learning.
- Keselman, H. J., Algina, J., & Kowalchuk, R. K. (2001). The analysis of repeated measures designs: A review. British Journal of Mathematical and Statistical Psychology, 54(1), 1–20. https://doi.org/10.1348/000711001159357
- Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: A practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4, 863. https://doi.org/10.3389/fpsyg.2013.00863
- Singmann, H., Bolker, B., Westfall, J., & Aust, F. (2024). afex: Analysis of factorial experiments [R package]. https://cran.r-project.org/package=afex
- American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). APA. https://doi.org/10.1037/0000165-000
- Bakeman, R. (2005). Recommended effect size statistics for repeated measures designs. Behavior Research Methods, 37(3), 379–384. https://doi.org/10.3758/BF03192707
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
- NIST/SEMATECH. (2013). e-Handbook of statistical methods. National Institute of Standards and Technology. https://www.itl.nist.gov/div898/handbook/