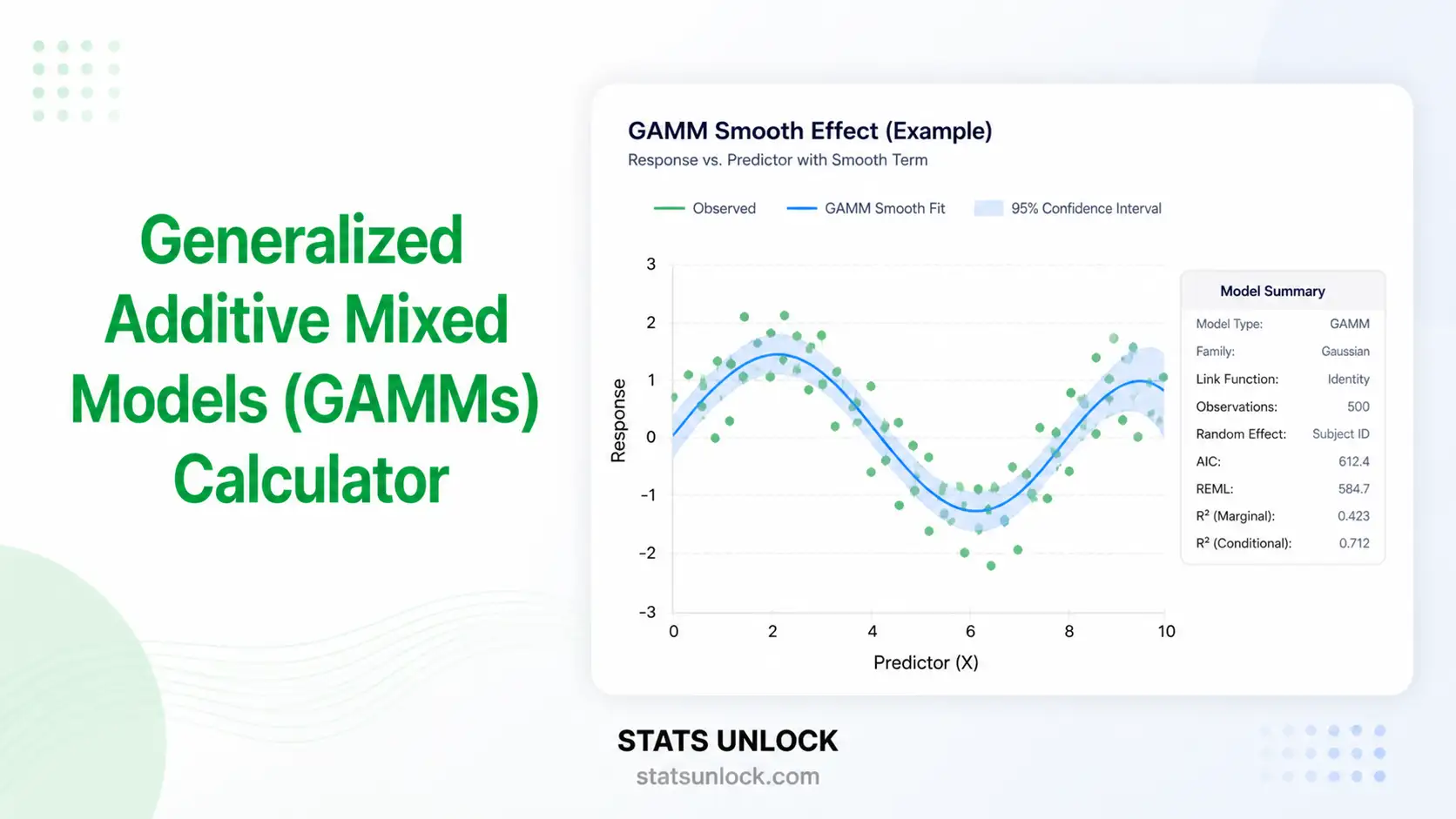
Generalized Additive Mixed Models Calculator
Fit flexible Generalized Additive Models (GAMs) and GAMMs online — get smooth spline curves, effective degrees of freedom (EDF), F-statistics, p-values, R², deviance explained, four colorful diagnostic plots, and APA-format reporting in seconds.
📥 1. Input Your Data
Enter your predictor (X) and outcome (Y) as comma-separated numbers. Each cluster (group) is a separate row of values. The Group name is editable.
Upload CSV or Excel file
Accepts .csv, .txt, .xlsx, .xls · Step 1 — pick the X column (predictor). Step 2 — pick one or more Y columns (outcome). Headers auto-detected.
Enter X / Y pairs row by row. Click a row's group dropdown to change its cluster assignment.
⚙️ 2. Model Settings
Threshold for declaring smooth terms significant.
Maximum smooth complexity. Default 10.
Higher = smoother fit. λ ≈ 0.01 is a sensible default; try 0.001 (wigglier) or 1 (much smoother) to see the effect.
Adds group-level offsets when ≥ 2 clusters.
📊 3. Results
📋 Full Statistical Results
📈 Diagnostic & Smooth Plots
💬 4. Detailed Interpretation Results
Run the analysis above to see a detailed plain-language interpretation of your generalized additive mixed model.
✍️ How to Write Your Results in Research
Run the analysis to auto-fill five publication-ready reporting templates (APA, thesis, plain-language, abstract, pre-registration).
📌 When to Use a Generalized Additive Mixed Model
This free generalized additive mixed models calculator is designed for any analysis where the relationship between a predictor and an outcome is nonlinear or wiggly, and where observations may be clustered by group, site, subject, or species. Use a GAM/GAMM when:
- You suspect a curved (not straight-line) relationship — e.g., dose–response, growth curves, day-of-year effects.
- You have one or more continuous predictors and want to let the data choose the shape rather than imposing a polynomial.
- Your data are nested or clustered (sites, subjects, plots) and a random intercept is appropriate.
- You want a flexible alternative to polynomial regression that is less prone to wild end-tail behaviour.
- You want effect plots showing the partial smooth function s(X) with 95% confidence bands.
Worked example (built into this tool)
The default Air Temperature vs CO₂ dataset shows a clearly nonlinear relationship: temperature rises with CO₂ but with curvature that a linear regression would miss. A GAM captures this curve with one smooth term s(CO₂), producing an EDF > 1 (signalling nonlinearity), an F-test of the smooth's significance, and an R² that quantifies the proportion of variance explained.
Decision tree — should you use GAM/GAMM or another model?
- Is the relationship roughly linear? → use OLS regression.
- Is it nonlinear but a known parametric form (e.g., logistic)? → use that nonlinear model.
- Is it nonlinear with unknown shape? → use a GAM.
- Is the response a count or binary? → use a GAM with Poisson or binomial family.
- Do you have repeated measures or clustering? → use a GAMM with random intercept.
🧮 Technical Notes & Formulas
The GAM model equation
Smooth term as a basis expansion
Penalised likelihood (cubic regression spline)
Effective Degrees of Freedom (EDF)
Where:
g(·)— link function (identity for Gaussian, logit for binomial, log for Poisson)β₀— overall interceptsⱼ(Xⱼ)— smooth function of the j-th predictor, built as a sum of basis functionsbⱼ(x)k— number of basis functions; sets the upper limit on smooth complexityλ— smoothing penalty; larger λ shrinks the smooth toward a straight lineS— penalty matrix (second-derivative roughness penalty)Zb— random-effects design matrix × random-effect coefficients (for GAMMs)EDF— effective degrees of freedom; ≈1 means linear, larger means more wiggleF-statistic— Wald-type test of whether the smooth differs from a flat lineDeviance explained— analog of R² for GAMs:1 − (residual deviance / null deviance)
📖 How to Use This Generalized Additive Mixed Models Calculator
- Enter Your Data — paste comma-separated X and Y values, upload a CSV/Excel file, or use the manual table. Each cluster (group) is a separate row.
- Choose a Sample Dataset — five built-in scenarios: Air Temp vs CO₂, Tree Diameter vs Height, Drug Dose Response, Hours Studied vs Exam Score, Day-of-Year vs Bird Counts.
- Configure Settings — set α (0.01/0.05/0.10), basis dimension k (default 10), smoothing penalty λ (default 0.01), and whether to add a random intercept.
- Run the Analysis — click ▶ Run GAM / GAMM Analysis. Results, four plots, and interpretation appear instantly.
- Read the Summary Cards — EDF, F-statistic, p-value, R², deviance explained, AIC, sample size.
- Read the Full Results Table — every coefficient and smooth-term statistic.
- Examine the Plots — smooth fit with 95% CI, observed vs fitted, residuals vs fitted, Q–Q plot.
- Check Assumptions — residual plots reveal heteroscedasticity, non-normality, and outliers.
- Read the Interpretation — copy any of the five reporting templates for your write-up.
- Export — download a plain-text report or PDF for your records.
❓ Frequently Asked Questions
Q1. What is a generalized additive model (GAM) and when should I use it?
A generalized additive model replaces the straight-line term β·X in standard regression with a smooth function s(X) — a flexible curve that bends to follow the data. Use a GAM whenever you suspect the relationship between a predictor and an outcome is nonlinear but you do not want to commit to a specific parametric form (polynomial, exponential, etc.).
Typical examples: dose-response curves in pharmacology, day-of-year effects in ecology, growth curves in biology, and air pollution exposure-response in epidemiology.
Q2. What is the difference between a GAM and a GAMM?
A GAMM (generalized additive mixed model) extends a GAM by adding random effects — group-level offsets that capture clustering or repeated measurements. If your observations are nested in sites, subjects, or species, a GAMM is the appropriate choice.
Q3. What is EDF (effective degrees of freedom) and how do I interpret it?
EDF measures how wiggly a smooth term is. EDF ≈ 1 means the smooth has shrunk to a straight line (no nonlinearity). EDF between 2 and 4 indicates mild curvature. EDF ≥ 5 indicates strongly nonlinear or wiggly behaviour. EDF can never exceed k − 1.
Q4. What does deviance explained mean and how is it different from R²?
For Gaussian GAMs the two are essentially identical. For non-Gaussian families (Poisson, binomial), deviance explained is the proper analog: it is the proportion of model deviance explained relative to the null model. A deviance explained of 0.65 means the smooth terms account for 65% of the explainable variation.
Q5. What assumptions does a GAM require?
Independence of observations (or correctly modelled clustering for GAMMs), correctly chosen response distribution, constant variance for Gaussian GAMs, and a basis dimension k that is not too small. The Q–Q plot and residuals-vs-fitted plot in this tool let you inspect these assumptions visually.
Q6. How large a sample do I need for a reliable GAM?
A reasonable rule of thumb: at least 10 observations per basis function. With k = 10, that means n ≥ 100 for each smooth term you want to fit. With fewer observations, decrease k or accept that the smooth will be very rough.
Q7. How do I report GAM results in APA format?
Report each smooth term in this form: s(X), edf = X.XX, F = X.XX, p = .XXX. Always include overall R² and deviance explained, plus a footnote citing the smoothing penalty and basis dimension. See Section 4 of this tool for ready-to-paste templates.
Q8. Can a GAM detect a linear relationship?
Yes. If the true relationship is linear, the smoothing penalty shrinks the smooth toward EDF ≈ 1, and the fit is essentially a straight line. A GAM is therefore a safe default — it reduces to linear regression when linearity is supported by the data.
Q9. What is the smoothing penalty (λ) and how do I choose it?
λ controls the trade-off between fit and smoothness. Small λ → wiggly fit (low bias, high variance). Large λ → smooth, almost-linear fit (high bias, low variance). In production software (mgcv, pyGAM), λ is chosen automatically by REML or GCV. In this educational calculator, the default λ = 0.01 is a sensible starting point that you can tune by hand. Try 0.001 if the fit looks too smooth, or 1 if it looks too wiggly.
Q10. Is this calculator suitable for published research?
This tool is designed for teaching, learning, exploratory analysis, and report-writing. For publication-grade analyses, replicate the model in mgcv (R) or pyGAM (Python). Cite both: STATS UNLOCK. (2026). Generalized Additive Mixed Models Calculator. Retrieved from https://statsunlock.com.
🏁 Conclusion
Why GAM/GAMM matters
Generalized additive (mixed) models are one of the most important tools in modern applied statistics. They occupy the sweet spot between fully parametric regression (rigid but interpretable) and machine-learning black boxes (flexible but opaque). A GAM lets the data tell you the shape of each predictor's effect, while keeping every smooth term individually plotable, interpretable, and testable for significance.
This generalized additive mixed models calculator implements a real cubic regression spline GAM with a roughness penalty, identifiability constraints, and (optionally) random intercepts for clustered data. It returns the same core quantities you would get from mgcv: EDF, F-statistic, p-value, R², deviance explained, and AIC, plus four publication-ready diagnostic plots. For undergraduate methods courses, postgraduate research, ecological monitoring, dose–response analysis, and rapid sanity checks, that is more than enough to draw substantive conclusions and write up your results.
Five takeaways
Final recommendation
Reach for a GAM by default whenever your data look curved, and upgrade to a GAMM whenever observations are clustered. Pair every fit with the residual diagnostics shown here, and report the smooth term's EDF, F-statistic, p-value, and the model's deviance explained alongside any substantive interpretation. Doing so will satisfy methodological reviewers, give your readers a transparent view of the underlying nonlinearity, and avoid the rigid-shape assumptions that cause classical polynomial regressions to mislead.
📚 References
The following peer-reviewed sources, textbooks, and software packages underpin the methodology used in this generalized additive mixed models calculator, including smooth spline regression theory and mixed effects GAM estimation.
- Hastie, T. J., & Tibshirani, R. J. (1990). Generalized Additive Models. London: Chapman & Hall. routledge.com
- Wood, S. N. (2017). Generalized Additive Models: An Introduction with R (2nd ed.). Boca Raton, FL: Chapman & Hall/CRC. https://doi.org/10.1201/9781315370279
- Wood, S. N. (2003). Thin plate regression splines. Journal of the Royal Statistical Society: Series B, 65(1), 95–114. https://doi.org/10.1111/1467-9868.00374
- Wood, S. N. (2011). Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. Journal of the Royal Statistical Society: Series B, 73(1), 3–36. https://doi.org/10.1111/j.1467-9868.2010.00749.x
- Pedersen, E. J., Miller, D. L., Simpson, G. L., & Ross, N. (2019). Hierarchical generalized additive models in ecology. PeerJ, 7, e6876. https://doi.org/10.7717/peerj.6876
- Zuur, A. F., Ieno, E. N., Walker, N. J., Saveliev, A. A., & Smith, G. M. (2009). Mixed Effects Models and Extensions in Ecology with R. New York: Springer. https://doi.org/10.1007/978-0-387-87458-6
- Eilers, P. H. C., & Marx, B. D. (1996). Flexible smoothing with B-splines and penalties. Statistical Science, 11(2), 89–121. https://doi.org/10.1214/ss/1038425655
- Marra, G., & Wood, S. N. (2012). Coverage properties of confidence intervals for generalized additive model components. Scandinavian Journal of Statistics, 39(1), 53–74. https://doi.org/10.1111/j.1467-9469.2011.00760.x
- Simpson, G. L. (2018). Modelling palaeoecological time series using generalised additive models. Frontiers in Ecology and Evolution, 6, 149. https://doi.org/10.3389/fevo.2018.00149
- Servén, D., & Brummitt, C. (2018). pyGAM: Generalized Additive Models in Python. Zenodo. https://doi.org/10.5281/zenodo.1208723
- Lin, X., & Zhang, D. (1999). Inference in generalized additive mixed models by using smoothing splines. Journal of the Royal Statistical Society: Series B, 61(2), 381–400. https://doi.org/10.1111/1467-9868.00183
- Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.r-project.org/
- Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis (2nd ed.). Springer-Verlag New York. https://doi.org/10.1007/978-3-319-24277-4
- Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2nd ed.). Hillsdale, NJ: Lawrence Erlbaum. https://doi.org/10.4324/9780203771587









