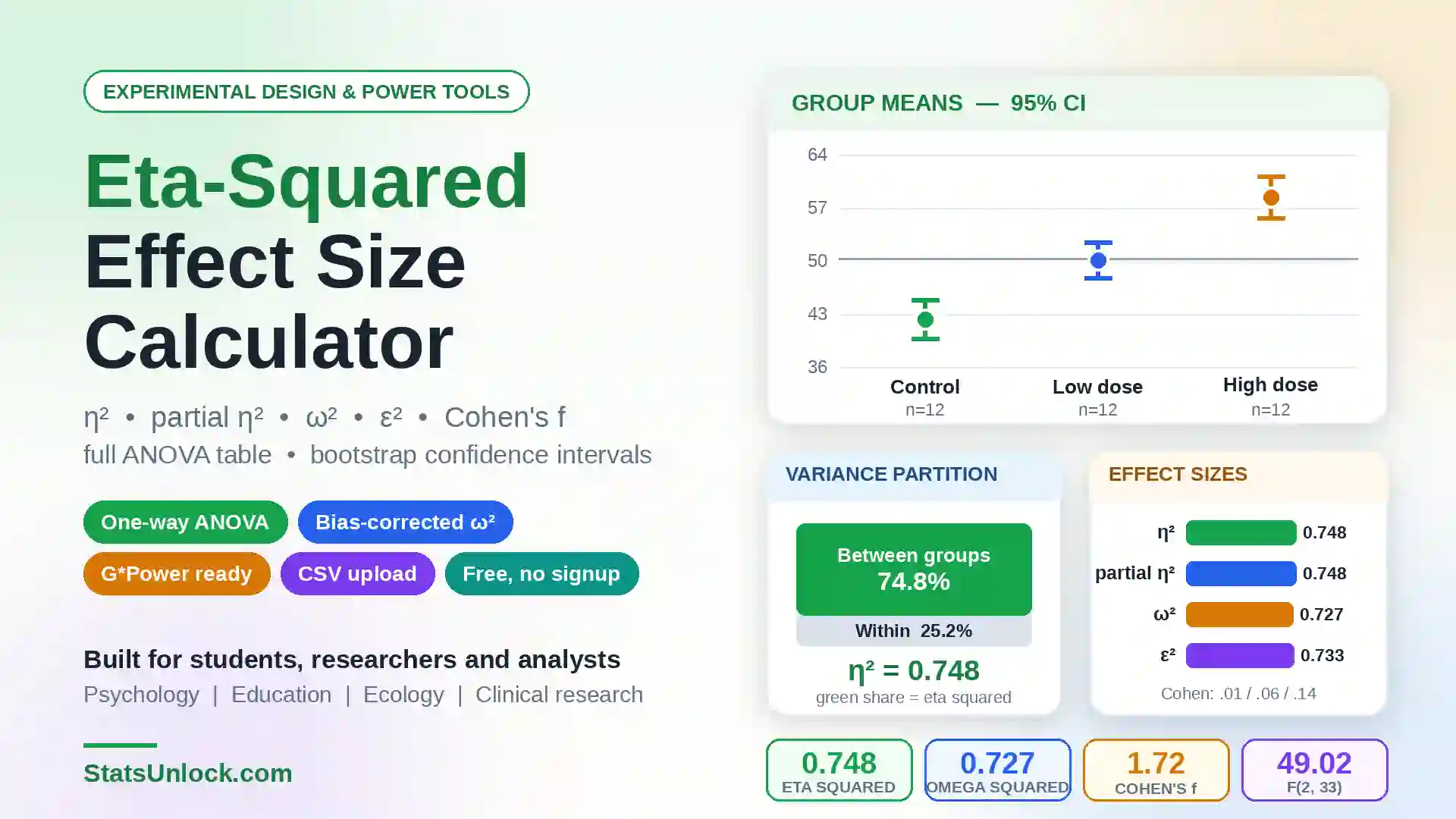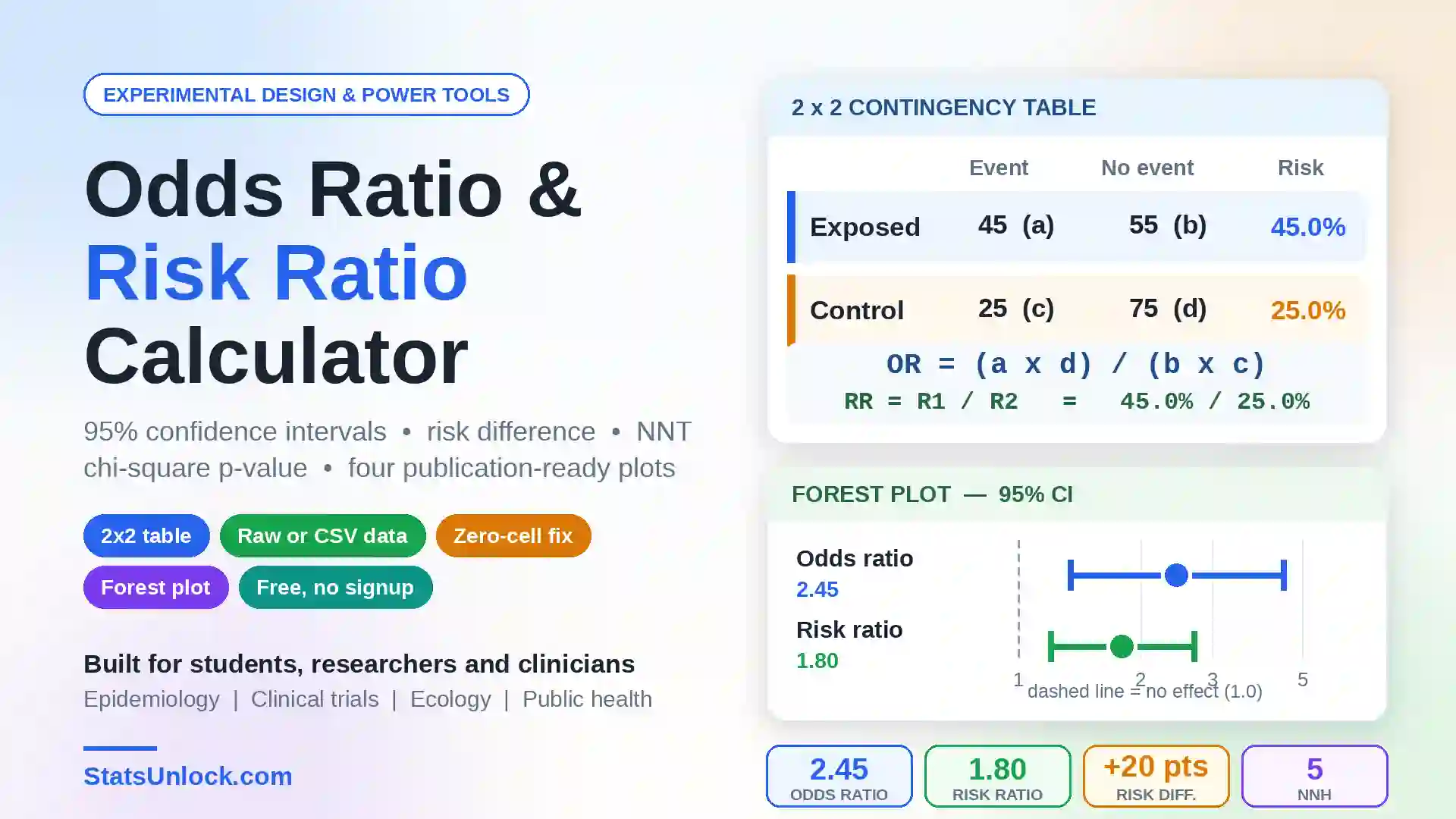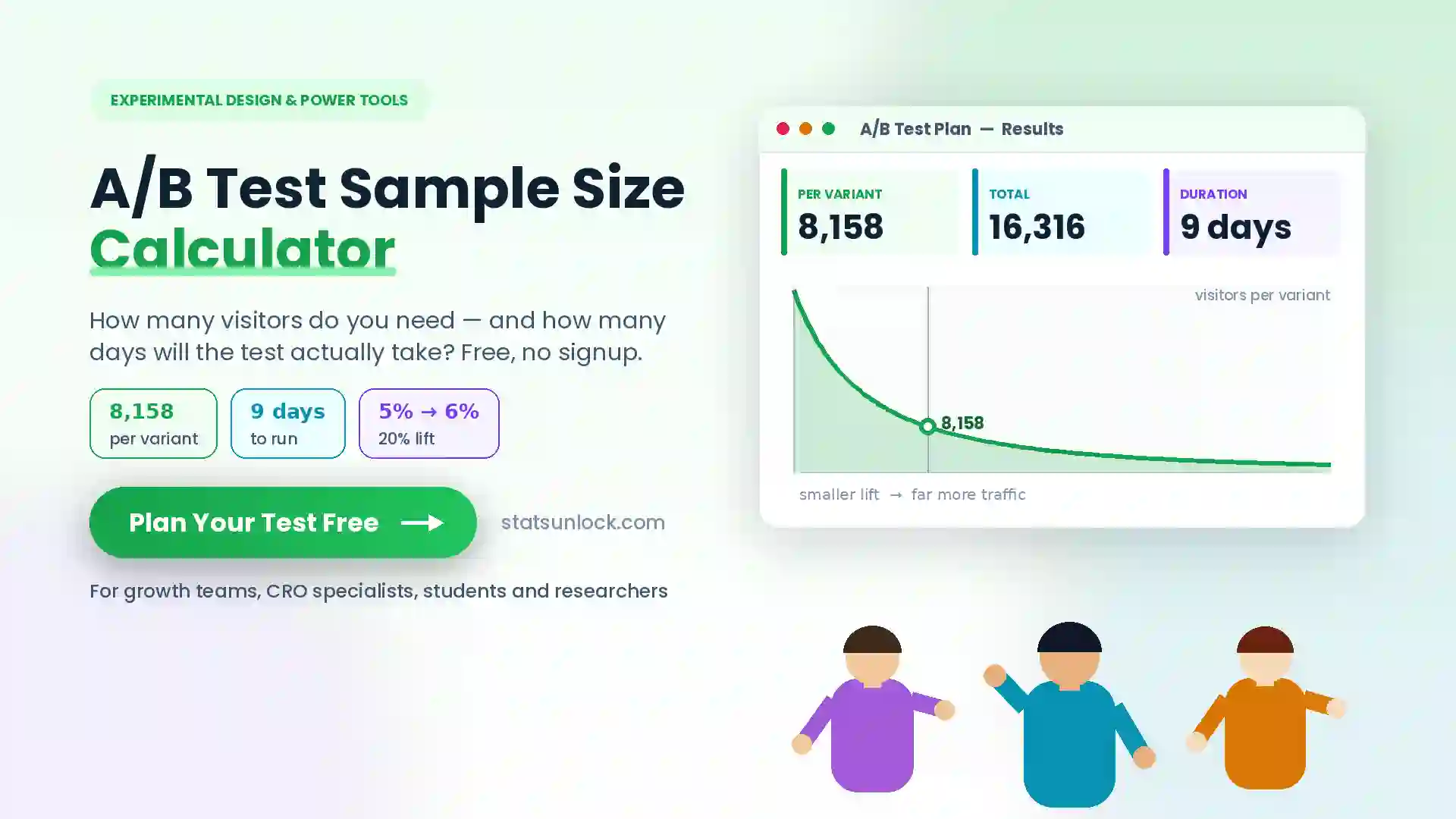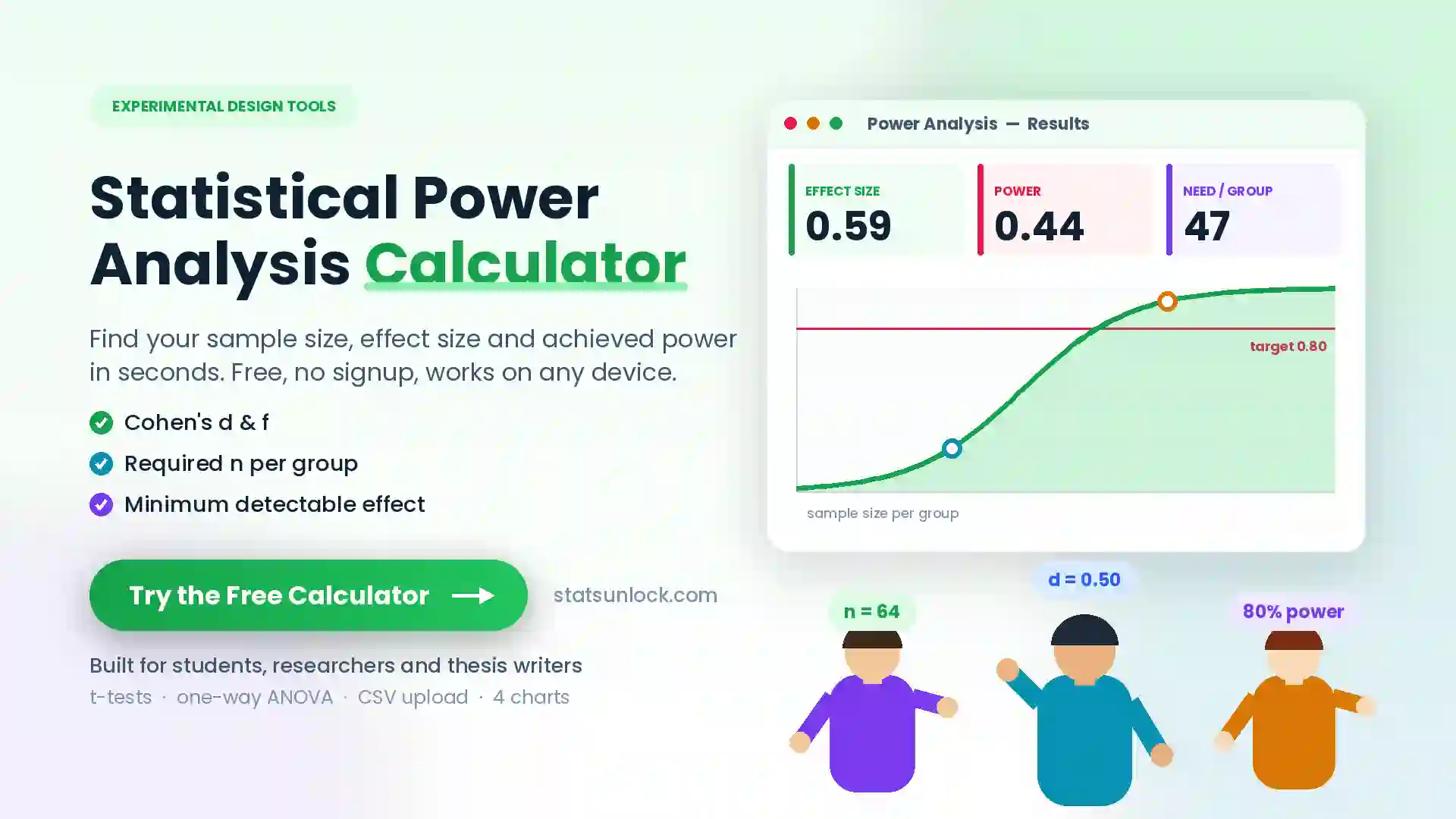
Hill Numbers Calculator (⁰D, ¹D, ²D)
Compute the effective number of species across diversity orders q = 0, 1, 2 — a unified, scale-comparable family of biodiversity indices for ecology and wildlife research.
📥 Input Data
📊 Results Summary
Hill Numbers Equation
The Hill number of order q for a community of S species with relative abundances pi is defined as:
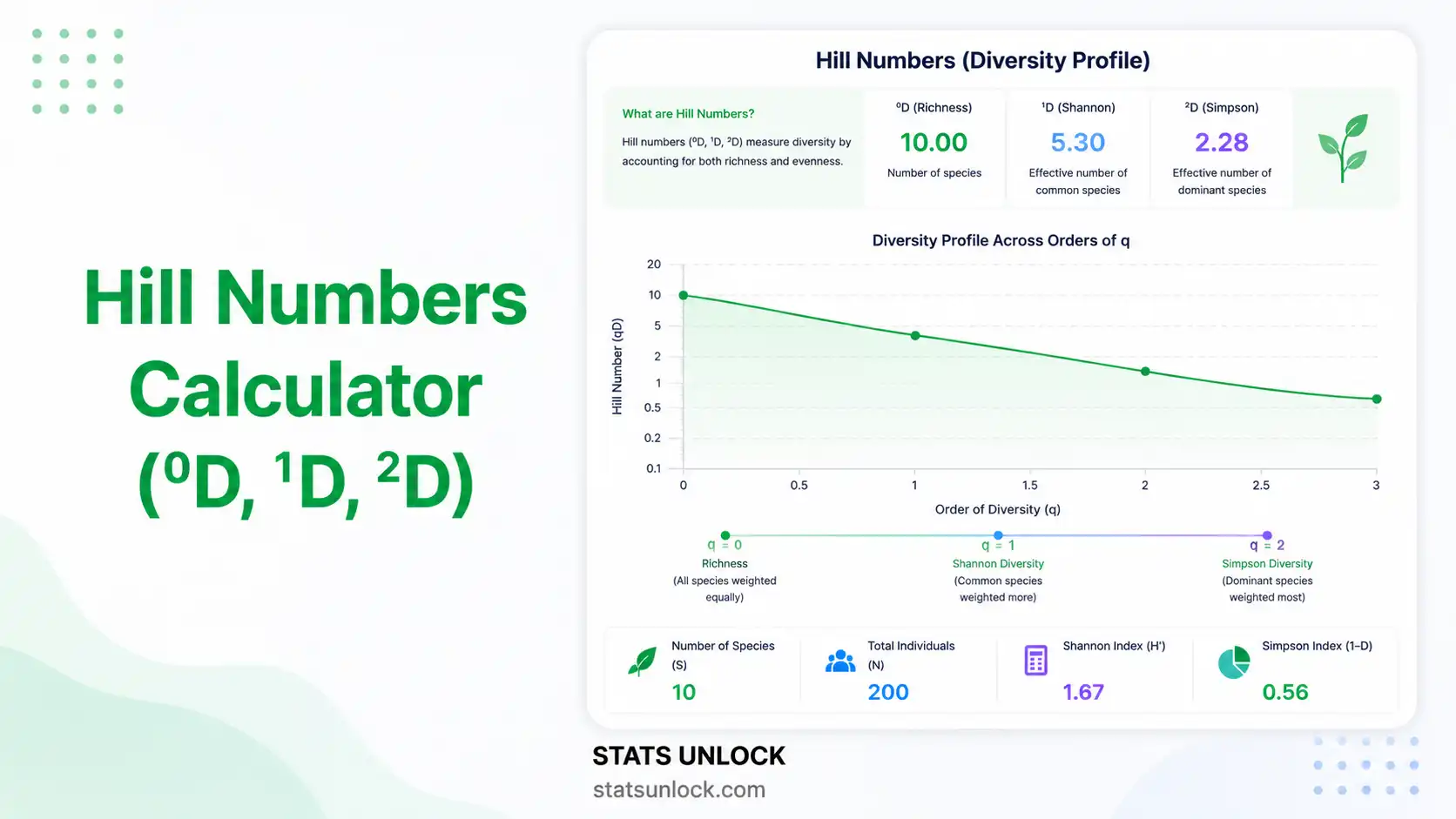
Special cases: ⁰D = S (richness) · ¹D = exp(H′) · ²D = 1 / Σpᵢ²
- ᵠD: Hill number of order q — the effective number of equally abundant species
- q: order of diversity (sensitivity to rare species; q = 0, 1, 2)
- S: total species richness (number of distinct species)
- pi: relative abundance of species i = ni / N
- ni: number of individuals of species i
- N: total number of individuals across all species
- H′: Shannon entropy = −Σ pi ln pi
- Σ: summation over all S species
Full Results Table
📈 Visualizations
📊 Diversity Profile (qD vs q)
📉 Rank–Abundance (Whittaker)
🥧 Relative Abundance Distribution
📐 Hill Numbers Comparison Bars
🔬 Detailed Interpretation of Results
✍️ How to Write Your Results in Research
🪧 Research Poster Panel — Advanced & Detailed
A print-ready, conference-grade poster panel auto-built from your Hill numbers result. Copy the entire poster, refine in your own designer, and submit.
🌿 Detailed Conclusion
❓ Frequently Asked Questions
Q1. What are Hill numbers and when should I use them?
Hill numbers are a unified family of biodiversity indices proposed by Mark Hill (1973) and popularised by Lou Jost (2006). Each Hill number is expressed as the effective number of equally abundant species — i.e. the number of species a perfectly even community would need to give the same diversity value. The order q controls sensitivity to rare species: q = 0 counts every species equally (richness), q = 1 weights species by Shannon entropy, q = 2 emphasises dominant species.
Use Hill numbers whenever you want diversity values that are directly comparable, additive, and on the same units (number of species) regardless of which order you compute. They are the modern recommended way to report biodiversity in peer-reviewed ecology.
Q2. What data do I need to calculate Hill numbers?
You need a list of species counts (abundances) from one community or sampling unit. Each value is the number of individuals (or detections, occurrences, or basal area) of one species. A minimum of 5 species and 30 individuals is recommended; 100+ individuals across replicate plots gives stable estimates of all three orders.
Counts of zero should be excluded. Decimal abundances (e.g., basal area, biomass) are accepted — Hill numbers do not require integer counts.
Q3. What is the difference between ⁰D, ¹D and ²D?
⁰D = S is species richness — every species counts equally regardless of abundance. It is the most sensitive to rare species and to under-sampling. ¹D = exp(H′) is the exponential of Shannon entropy and equals the effective number of common species. ²D = 1/Σp² is the inverse of Simpson's concentration and represents the effective number of dominant species.
The relationship ⁰D ≥ ¹D ≥ ²D always holds, with equality only when the community is perfectly even.
Q4. How do Hill numbers differ from Shannon and Simpson indices?
Shannon (H′) and Simpson (D, λ) are not on the same scale and cannot be added or compared directly. Hill numbers convert them to effective species counts: ¹D = exp(H′) and ²D = 1/λ. Hill numbers also have the doubling property: a community with ²D = 10 has twice the effective dominant diversity of one with ²D = 5 — a property H′ does not have.
Q5. What are the assumptions and limitations of Hill numbers?
Hill numbers assume a closed community with a complete species list, equal sampling effort across species, and accurate identification. They are sensitive to sample size for q = 0 (richness), less sensitive for q = 1, and least sensitive for q = 2. Rarefaction or coverage-based standardisation (Chao & Jost 2012) is recommended for cross-site comparisons.
Q6. How much sampling effort do I need for reliable Hill numbers?
At minimum, 30 individuals and 5 species; ideally 100+ individuals across replicate plots, transects, or trap nights. Camera-trap studies should aim for 1,000+ trap nights. Use a species accumulation curve to confirm sampling adequacy before relying on q = 0 (richness), which is the most effort-sensitive of the three orders.
Q7. Can I compare Hill numbers between sites or seasons?
Yes, but only if sampling effort is standardised or rarefied to the same coverage level. Use Chao & Jost (2012) coverage-based rarefaction for unequal effort. Hill numbers are ideal for comparison because all three orders are on the same units (effective species), allowing meaningful subtraction and ratios across sites or time points.
Q8. How do I report Hill numbers in an ecology journal?
Report all three orders together: ⁰D (species richness), ¹D (effective common species), ²D (effective dominant species), along with sample size N and survey effort. Cite Hill (1973) and Jost (2006). Include the diversity profile plot whenever possible — it is now considered best practice in biodiversity research.
Q9. Can I use this calculator for published research or a thesis?
Yes for exploratory analysis. For peer-reviewed publication, verify results with the iNEXT R package (Hsieh, Ma & Chao 2016) or the vegan package (Oksanen et al. 2022), which add bootstrap confidence intervals and rarefaction. Cite this tool as: Stats Unlock. (2026). Hill Numbers Calculator. https://statsunlock.com.
Q10. My Hill numbers seem unexpectedly high or low — what might have gone wrong?
Common issues: (a) zero counts mistakenly entered, (b) species pooled instead of separated, (c) one taxon dominating the sample inflates ⁰D but collapses ²D, (d) very small N produces unstable estimates. Check the raw input in the Manual Entry tab and re-run with a sample dataset to confirm the tool is behaving correctly.
📚 How to Use This Tool
Open the 10-step worked walkthrough
- Enter your data — paste comma-separated species counts (default), upload a CSV/Excel file and pick the column, or use the manual entry table. Example:
52, 48, 55, 61, 47, 38, 29, 22, 18, 14, 10, 7, 5, 3, 2(15 species). - Choose a sample dataset — five built-in USA ecological datasets cover high-diversity Appalachian forest birds, disturbed urban park communities, Yellowstone camera-trap mammals, Chesapeake Bay waterbirds, and Appalachian insect communities.
- Configure the Study Area name and Group name — both substitute into all reporting examples, the poster, and the conclusion.
- Click Calculate Hill Numbers — the tool computes ⁰D, ¹D and ²D plus the full diversity profile from q = 0 to q = 3 in steps of 0.1.
- Read the summary cards — green = high effective diversity, amber = moderate, red = low diversity / dominance-skewed assemblage.
- Read the full results table — shows S, N, all three Hill numbers, Shannon H′, Simpson λ, Pielou J′, Berger–Parker dominance, and evenness ratios E10 and E21.
- Examine all four visualisations — the diversity profile reveals dominance patterns at a glance; the rank-abundance plot shows community structure.
- Read the detailed interpretation — five paragraphs auto-filled with your computed values, written for both ecologists and non-specialists.
- Copy a reporting example — pick the journal, thesis, plain-language, abstract, or monitoring style that matches your audience.
- Export results — Download Doc (.txt) for editing or Download PDF for printing and submission.
🔗 Related Diversity Calculators
Hill numbers are a unifying framework — every classical diversity index is a Hill number in disguise. Pair this calculator with the related tools below to cross-validate your results, build a complete biodiversity report, and report your findings in a journal-ready format.
📖 References
The following references support the methods used in this Hill numbers calculator, covering biodiversity index theory, species diversity measurement, and best practices in ecological sampling.
- Hill, M. O. (1973). Diversity and evenness: A unifying notation and its consequences. Ecology, 54(2), 427–432. https://doi.org/10.2307/1934352
- Jost, L. (2006). Entropy and diversity. Oikos, 113(2), 363–375. https://doi.org/10.1111/j.2006.0030-1299.14714.x
- Jost, L. (2007). Partitioning diversity into independent alpha and beta components. Ecology, 88(10), 2427–2439. https://doi.org/10.1890/06-1736.1
- Chao, A., & Jost, L. (2012). Coverage-based rarefaction and extrapolation: Standardizing samples by completeness rather than size. Ecology, 93(12), 2533–2547. https://doi.org/10.1890/11-1952.1
- Chao, A., Chiu, C.-H., & Jost, L. (2014). Unifying species diversity, phylogenetic diversity, functional diversity, and related similarity and differentiation measures through Hill numbers. Annual Review of Ecology, Evolution, and Systematics, 45, 297–324. https://doi.org/10.1146/annurev-ecolsys-120213-091540
- Shannon, C. E., & Weaver, W. (1949). The mathematical theory of communication. University of Illinois Press.
- Simpson, E. H. (1949). Measurement of diversity. Nature, 163, 688. https://doi.org/10.1038/163688a0
- Magurran, A. E. (2004). Measuring biological diversity. Blackwell Publishing.
- Pielou, E. C. (1966). The measurement of diversity in different types of biological collections. Journal of Theoretical Biology, 13, 131–144. https://doi.org/10.1016/0022-5193(66)90013-0
- Hsieh, T. C., Ma, K. H., & Chao, A. (2016). iNEXT: An R package for rarefaction and extrapolation of species diversity (Hill numbers). Methods in Ecology and Evolution, 7(12), 1451–1456. https://doi.org/10.1111/2041-210X.12613
- Oksanen, J., Simpson, G. L., Blanchet, F. G., et al. (2022). vegan: Community ecology package (R package version 2.6-4). https://CRAN.R-project.org/package=vegan
- Gotelli, N. J., & Colwell, R. K. (2001). Quantifying biodiversity: Procedures and pitfalls in the measurement and comparison of species richness. Ecology Letters, 4(4), 379–391. https://doi.org/10.1046/j.1461-0248.2001.00230.x
- Tuomisto, H. (2010). A diversity of beta diversities: Straightening up a concept gone awry. Ecography, 33(1), 2–22. https://doi.org/10.1111/j.1600-0587.2009.05880.x
- Krebs, C. J. (1999). Ecological methodology (2nd ed.). Benjamin Cummings.
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/