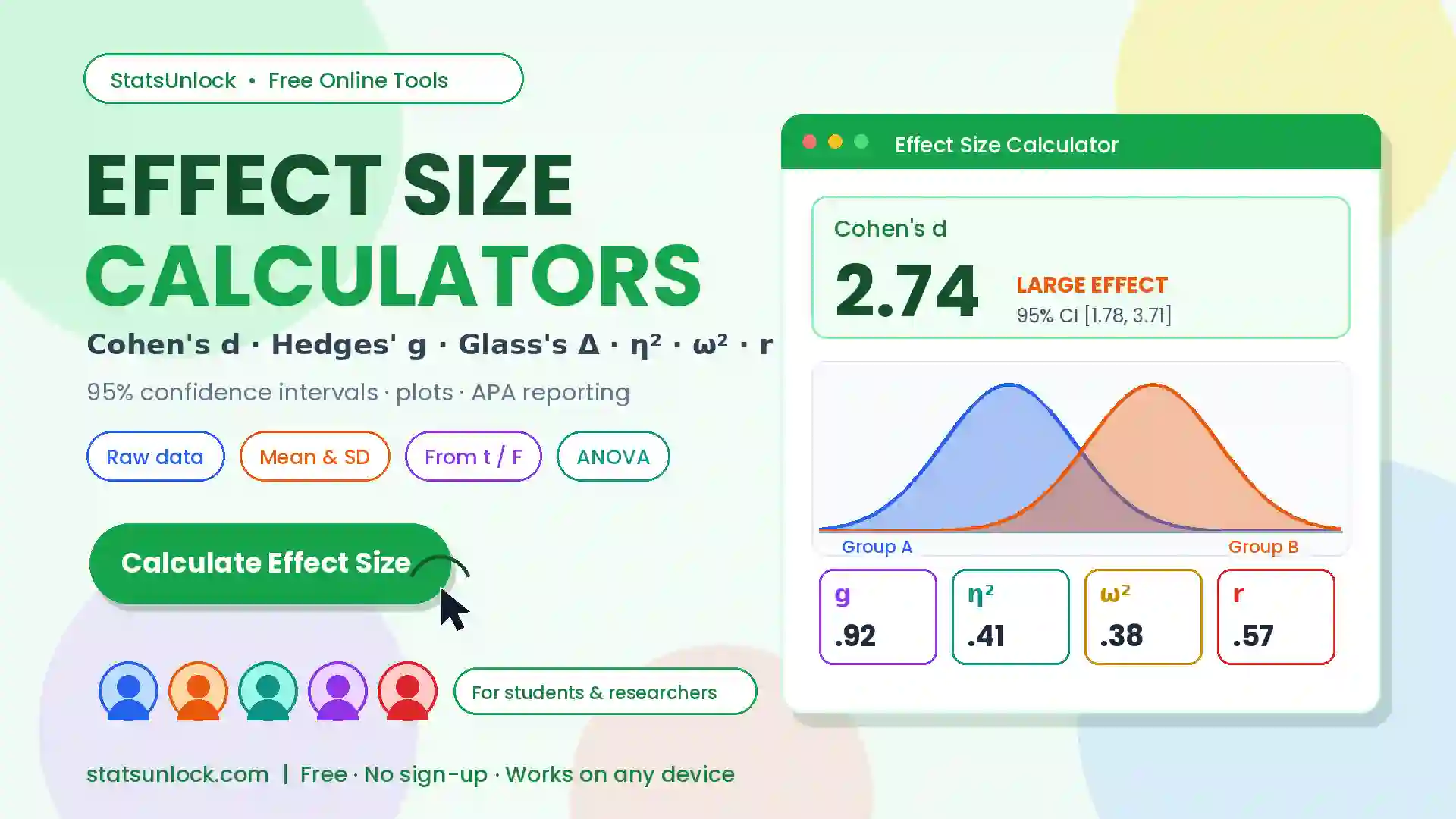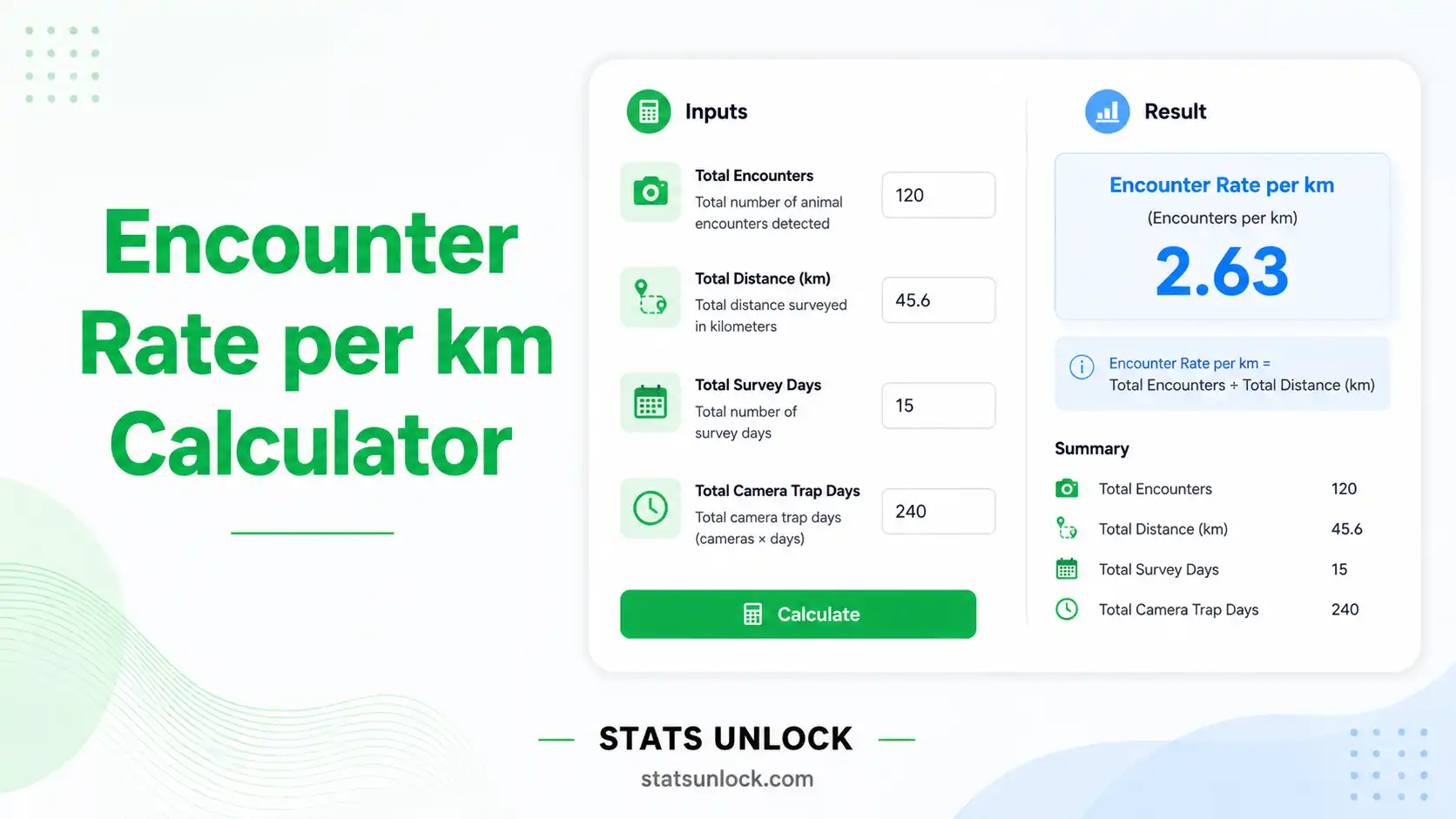
Encounter Rate per km Calculator
Calculate wildlife encounter rate (detections per km), mean, SE, and 95% confidence interval from transect surveys.
📥 Data Input
| Transect ID | Detections | Distance (km) |
|---|
⚙️ Analysis Configuration
🔍 Conclusion
▶ Run the analysis above to generate a personalised conclusion for your dataset.
📐 Technical Notes — Formula Derivation, Assumptions & Limitations
Extended Formula Derivation
Encounter rate is a relative abundance index. For a single transect of length Li kilometers with ni detections, the per-transect rate is:
ERi = ni / Li
The sample-level mean encounter rate is the arithmetic mean across k replicate transects:
Mean ER = (1/k) Σ ERi
Standard error of the mean: SE = SD / √k, where SD is the sample standard deviation of per-transect ER values. The 95% confidence interval uses the t-distribution with k−1 degrees of freedom: CI = Mean ± t0.975, k−1 × SE.
Assumptions
- Detection probability is constant across all transects (or at least comparable).
- Each detection represents a single, independent encounter — no double-counting individuals.
- Survey method, observer skill, time-of-day, and weather are standardized.
- Habitat visibility along transects is similar (no closed canopy vs open field bias).
- Transects are independent — separated by enough distance to avoid spatial autocorrelation.
Limitations
- Does not correct for imperfect detection — use occupancy models (MacKenzie et al. 2002) when this matters.
- Does not estimate absolute density — use distance sampling (Buckland et al. 2001) for density.
- Sensitive to small samples; minimum 8–12 replicate transects recommended.
- Comparing across studies is risky unless methodology is identical.
🎯 When to Use This Tool
Decision Checklist
- ✓ You walked replicate transects of known length and recorded detections per transect
- ✓ You want to compare wildlife abundance across sites, seasons, or treatments
- ✓ Your survey effort is standardized (similar observer, time, method)
- ✓ You need a publication-ready relative abundance index
- ✗ Do NOT use if you need absolute density → use distance sampling instead
- ✗ Do NOT use if detection probability varies strongly across sites → use occupancy models
- ✗ Do NOT use if you only have presence/absence data → use occupancy or naive presence
USA Real-World Examples
- White-tailed deer monitoring — spotlight counts along forest roads in Pennsylvania State Forests to track herd trends across hunting seasons.
- Black bear sign surveys — walking transects in Great Smoky Mountains National Park to record scat, tracks, and bear-scarred trees.
- Mule deer aerial transects — fixed-wing surveys in Yellowstone Northern Range counting deer detections per km of flight path.
- Pollinator transect walks — Pollard walks at USDA-funded prairie restoration sites in the Midwest, recording bee and butterfly detections per km of transect.
Sampling Design Guidance
- Minimum 8–12 replicate transects per site for reliable mean and CI estimation.
- Transect length ≥ 1 km for mammals; ≥ 200 m for birds and pollinators.
- Repeat surveys across seasons to capture phenological variation.
- Walk at a constant pace (~2–3 km/h) to standardize detection probability.
Related Metrics — Decision Tree
Need a relative abundance index? → Encounter Rate (this tool) → Camera traps? → Relative Abundance Index (RAI) → Need absolute density? → Distance Sampling / Density Calculator → Need to correct for detection probability? → Occupancy Model → Multiple species? → Community-level Encounter Rate
📘 How to Use This Tool — Step-by-Step Guide
- Step 1 — Enter your data. Use the Paste/Type tab and enter detections per transect (e.g., 52, 48, 55, 61, 47) and matching distances in km (e.g., 3.2, 2.8, 3.0, 3.5, 2.7). Column Entry mode lets you label each transect (e.g., "Transect A — Riparian").
- Step 2 — Choose a USA sample dataset. Five regional examples are pre-loaded: White-tailed deer in Pennsylvania State Forests, Black bear sign in Great Smoky Mountains NP, Mule deer in Yellowstone, Coyote sign in Texas Hill Country, and Wild turkey in Missouri Ozarks.
- Step 3 — Configure analysis settings. Set the study area name (e.g., "Pennsylvania State Forest"), target species (e.g., "White-tailed Deer"), distance unit, and confidence level (90/95/99%).
- Step 4 — Run the analysis. Click "▶ Run Encounter Rate Analysis". The tool computes per-transect ER, mean, SD, SE, and CI.
- Step 5 — Read the summary cards. Dark green = very high (≥10 det/km, e.g. spotlight counts of deer), green = high (2–10 det/km), amber = moderate (0.5–2 det/km), red = low (<0.5 det/km). The tier is based on detections/km thresholds for North American wildlife.
- Step 6 — Read the full results table. Total detections, total distance walked, sample size, mean, SD, SE, 95% CI, and coefficient of variation are shown with descriptions.
- Step 7 — Examine the four visualizations. Bar chart of per-transect ER, histogram of distribution, scatter of detections vs distance, and mean ± CI plot.
- Step 8 — Read the detailed interpretation. Five paragraphs explain what your encounter rate means ecologically, what its magnitude implies, and what limitations apply.
- Step 9 — Copy a reporting example. Six examples: journal article, thesis, plain-language summary, conference abstract, monitoring report, and research poster.
- Step 10 — Export your results. Download as plain-text Doc or print-ready PDF. Both include the full interpretation and references.
❓ Frequently Asked Questions
Q1. What is encounter rate per km and when should I use it?
Encounter rate per km (ER) is the number of animal detections divided by the kilometers walked along a survey transect. It is the standard relative abundance index for line-transect and walk-transect surveys. Use it when you have replicate transects of known length and want to compare wildlife abundance across sites, seasons, or treatments — for example, comparing white-tailed deer detections across managed and unmanaged USA forest stands.
Q2. What data do I need to calculate encounter rate?
You need two columns: (1) number of detections per transect (sightings, signs, calls, scats, or any standardized observation) and (2) length of each transect in kilometers. Both Paste, Upload (CSV/Excel), and Manual Entry tabs accept this format. A minimum of 8–12 transects is recommended for reliable confidence intervals.
Q3. What does a high vs low encounter rate mean ecologically?
Interpretation is species-specific. For large mammals in USA national parks, < 0.1 detections/km is low, 0.1–1.0 is moderate, and > 1.0 is high. For abundant species like white-tailed deer in productive habitat, encounter rates can exceed 15 detections/km in spotlight counts. Always compare against regional baselines from peer-reviewed literature.
Q4. How does encounter rate differ from density?
Encounter rate is an index of relative abundance — it does not correct for the fact that some animals are missed. Density (individuals/km²) is the true number of animals per unit area and requires distance sampling, mark-recapture, or occupancy models with explicit detection probability estimation. Use encounter rate for trends and comparisons; use density when you need absolute population estimates.
Q5. What are the assumptions and limitations of encounter rate?
Key assumptions: constant detection probability across transects, no double-counting, standardized survey method, and similar habitat visibility. Violations bias results. Main limitations: cannot estimate density, sensitive to observer skill, and not directly comparable across studies with different methodologies. Use rarefaction or randomization tests for rigorous comparison.
Q6. How many transects do I need for encounter rate to be reliable?
At least 8 transects for a stable mean and 10–12 for reliable 95% CI estimation. Each transect should be ≥ 1 km for mammals and ≥ 200 m for birds. If your coefficient of variation (CV = SD/mean) exceeds 50%, increase sample size or extend transect length to reduce variance.
Q7. Can I compare encounter rate values between sites or time periods?
Yes, but only when survey effort, observer, season, time of day, weather, and detection conditions are standardized. Use a two-sample t-test or Mann-Whitney U test for two sites, ANOVA or Kruskal-Wallis for more than two. For time series, fit a linear or generalized linear model with year as a predictor.
Q8. How do I report encounter rate in an ecology journal?
Report the mean ER ± SE (or 95% CI), the number of transects (n), total distance walked, and total detections. Example: "Mean encounter rate of white-tailed deer was 16.4 ± 1.2 detections/km (n = 10 transects, 29.1 km total, 478 detections) in the Pennsylvania State Forest study site." See the six reporting examples in Section 2.7 above.
Q9. Can I use this calculator for published research or a USA university thesis?
Yes for exploratory analysis, teaching, and preliminary reporting. For peer-reviewed publications, cross-validate with R packages such as Distance, unmarked, or spaceNtime. Cite this tool as: "STATS UNLOCK. (2025). Encounter Rate per km Calculator. https://statsunlock.com".
Q10. My encounter rate seems unusually high or low — what could be wrong?
Common issues: (1) transect lengths entered in meters instead of km — multiply by 1000 or convert; (2) one transect with an unusually short length inflating its ER; (3) double-counting individuals; (4) mixing detection types (sightings + signs); (5) data entry errors. Verify the input in the Manual Entry tab and compare to the sample USA datasets to confirm the tool is working correctly.
📚 References
The following references support the statistical and ecological methods used in this encounter rate per km calculator, covering wildlife transect surveys, relative abundance estimation, and best practices in ecological sampling for USA wildlife monitoring.
- Buckland, S. T., Anderson, D. R., Burnham, K. P., Laake, J. L., Borchers, D. L., & Thomas, L. (2001). Introduction to distance sampling: Estimating abundance of biological populations. Oxford University Press. https://global.oup.com/academic/product/introduction-to-distance-sampling-9780198506492
- Burnham, K. P., & Anderson, D. R. (1980). Estimation of density from line transect sampling of biological populations. Wildlife Monographs, 72, 1–202. https://www.jstor.org/stable/3830641
- Krebs, C. J. (1999). Ecological methodology (2nd ed.). Benjamin Cummings. https://www.zoology.ubc.ca/~krebs/books.html
- MacKenzie, D. I., Nichols, J. D., Lachman, G. B., Droege, S., Royle, J. A., & Langtimm, C. A. (2002). Estimating site occupancy rates when detection probabilities are less than one. Ecology, 83(8), 2248–2255. https://doi.org/10.1890/0012-9658(2002)083[2248:ESORWD]2.0.CO;2
- Sutherland, W. J. (Ed.). (2006). Ecological census techniques: A handbook (2nd ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511790508
- Thomas, L., Buckland, S. T., Rexstad, E. A., Laake, J. L., Strindberg, S., Hedley, S. L., Bishop, J. R. B., Marques, T. A., & Burnham, K. P. (2010). Distance software: Design and analysis of distance sampling surveys for estimating population size. Journal of Applied Ecology, 47(1), 5–14. https://doi.org/10.1111/j.1365-2664.2009.01737.x
- Pollard, E. (1977). A method for assessing changes in the abundance of butterflies. Biological Conservation, 12(2), 115–134. https://doi.org/10.1016/0006-3207(77)90065-9
- Bibby, C. J., Burgess, N. D., Hill, D. A., & Mustoe, S. H. (2000). Bird census techniques (2nd ed.). Academic Press. https://www.elsevier.com/books/bird-census-techniques/bibby/978-0-12-095831-3
- Fiske, I. J., & Chandler, R. B. (2011). unmarked: An R package for fitting hierarchical models of wildlife occurrence and abundance. Journal of Statistical Software, 43(10), 1–23. https://doi.org/10.18637/jss.v043.i10
- White, G. C., & Burnham, K. P. (1999). Program MARK: Survival estimation from populations of marked animals. Bird Study, 46(sup1), S120–S139. https://doi.org/10.1080/00063659909477239
- USDA Forest Service. (2022). Field methods for wildlife monitoring on national forests. USFS General Technical Report. https://www.fs.usda.gov/research/
- USGS. (2023). North American Breeding Bird Survey methods. Patuxent Wildlife Research Center. https://www.pwrc.usgs.gov/bbs/
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
- Royle, J. A., & Nichols, J. D. (2003). Estimating abundance from repeated presence-absence data or point counts. Ecology, 84(3), 777–790. https://doi.org/10.1890/0012-9658(2003)084[0777:EAFRPA]2.0.CO;2