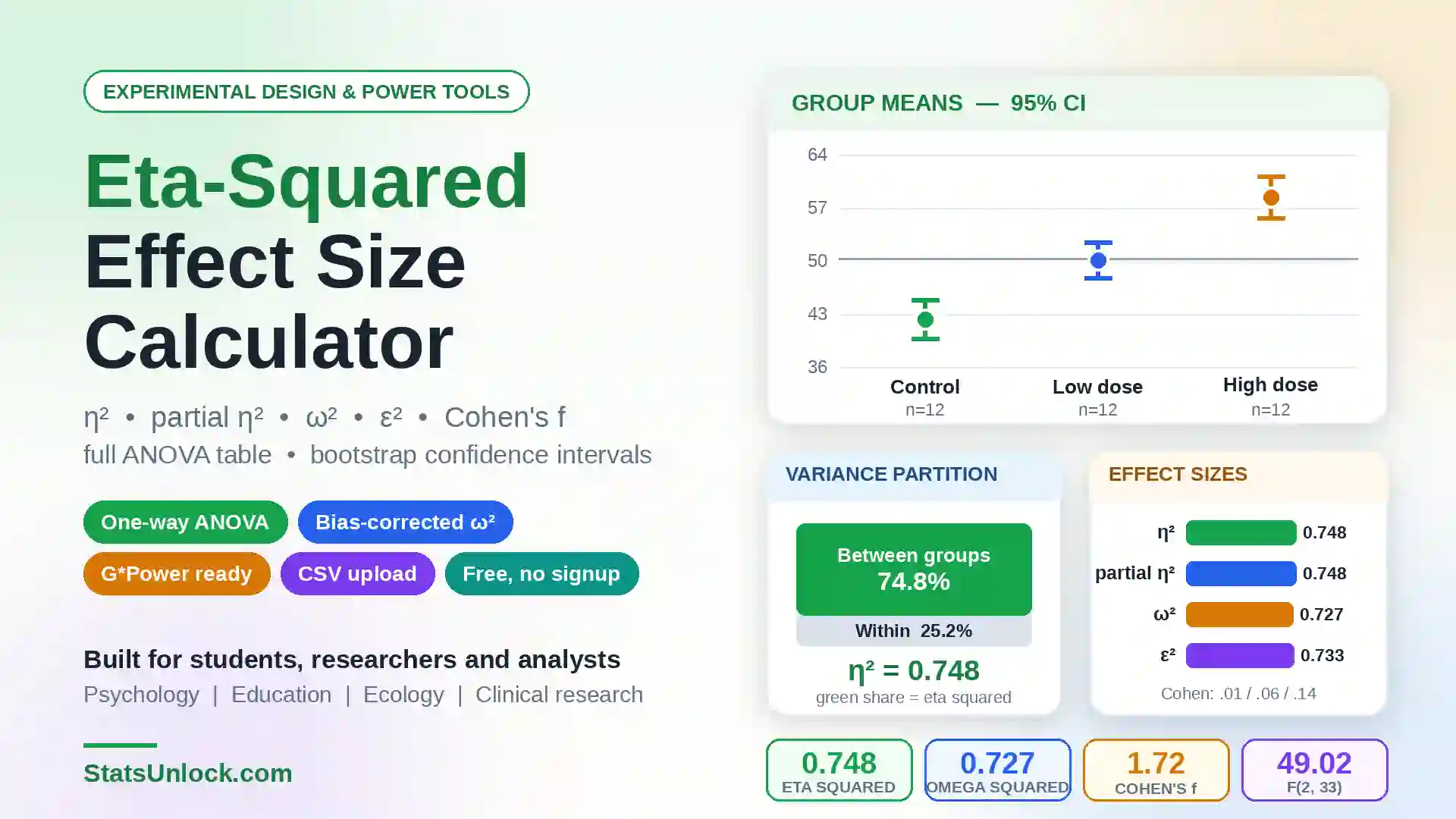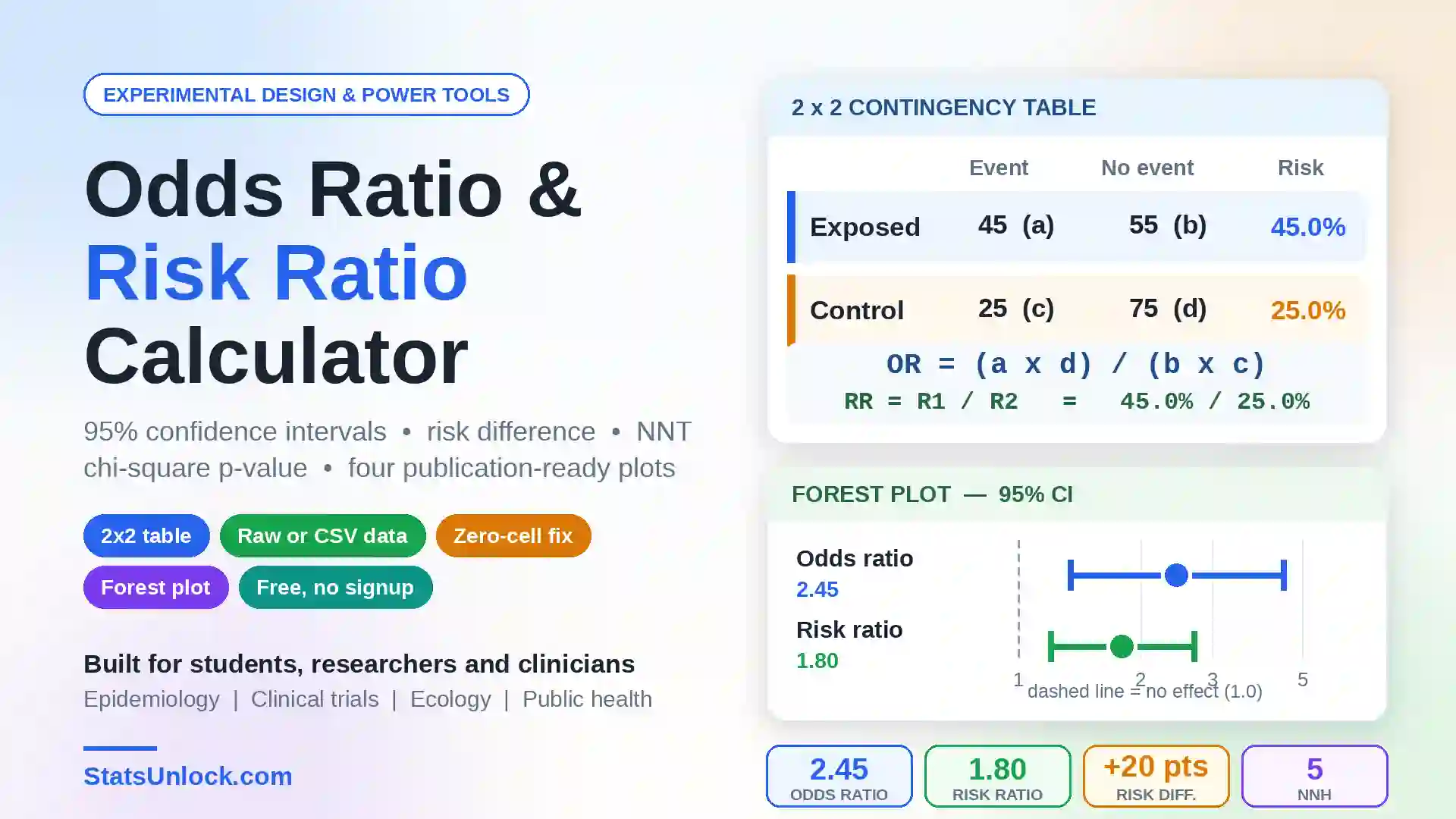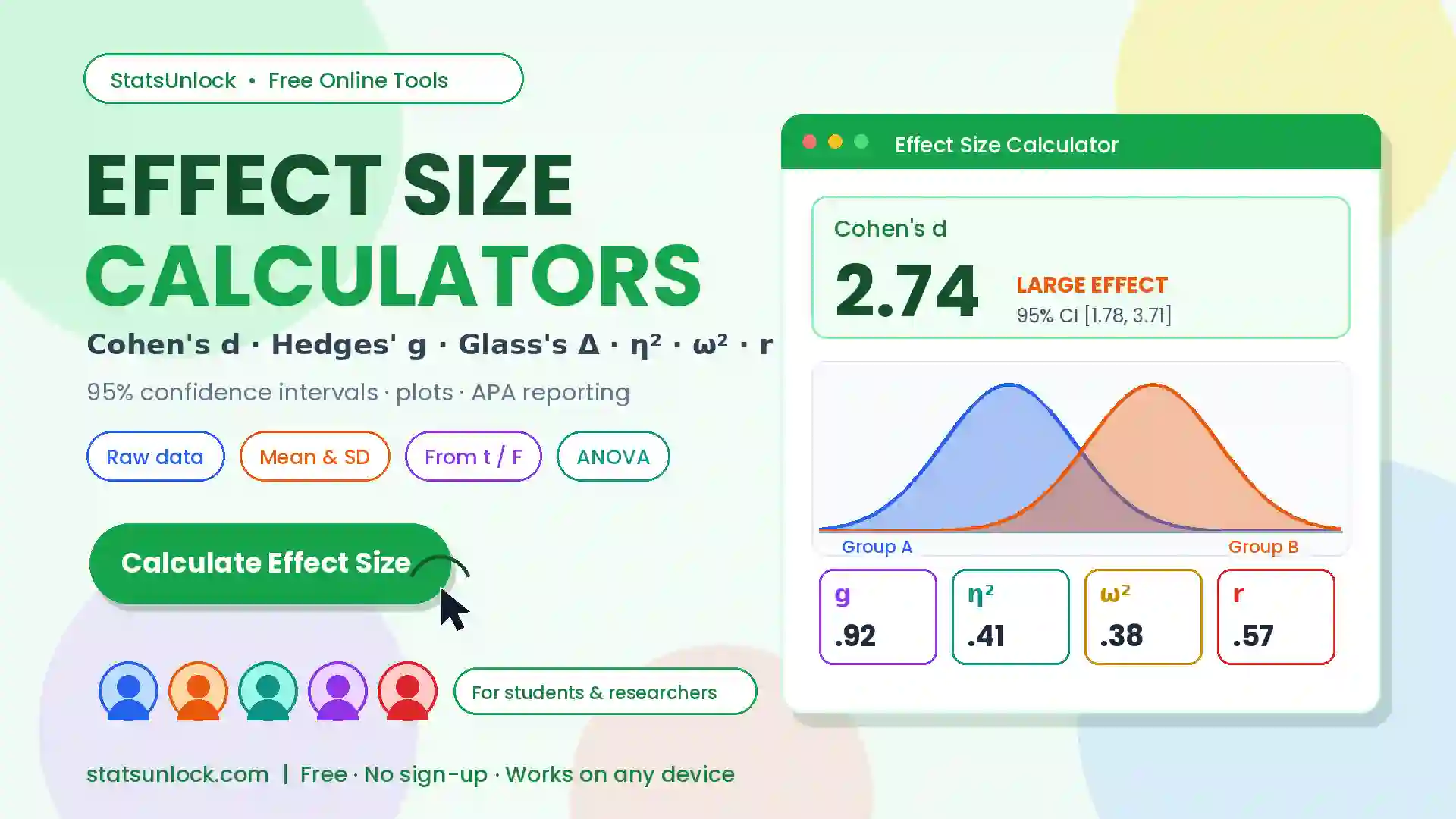
Independent Samples t-Test Calculator
Compare two group means with Welch's or Student's t-test — get p-values, Cohen's d effect size, Levene's test, confidence intervals, four visualizations, and APA write-up templates. Supports CSV & Excel upload.
What is an Independent Samples t-Test?
The independent samples t-test (also called the two-sample t-test or two-group t-test) is a parametric statistical test that compares the means of two separate, unrelated groups to determine whether the observed difference is statistically significant or likely due to chance. It is one of the most widely used hypothesis tests in medical, social, biological, and behavioral research.
This calculator supports both Welch's t-test (recommended — does not assume equal variances) and Student's t-test (assumes equal variances). It also runs Levene's test automatically to check the variance assumption, and computes Cohen's d to quantify the practical magnitude of any difference found.
| Statistic | Value | Description |
|---|
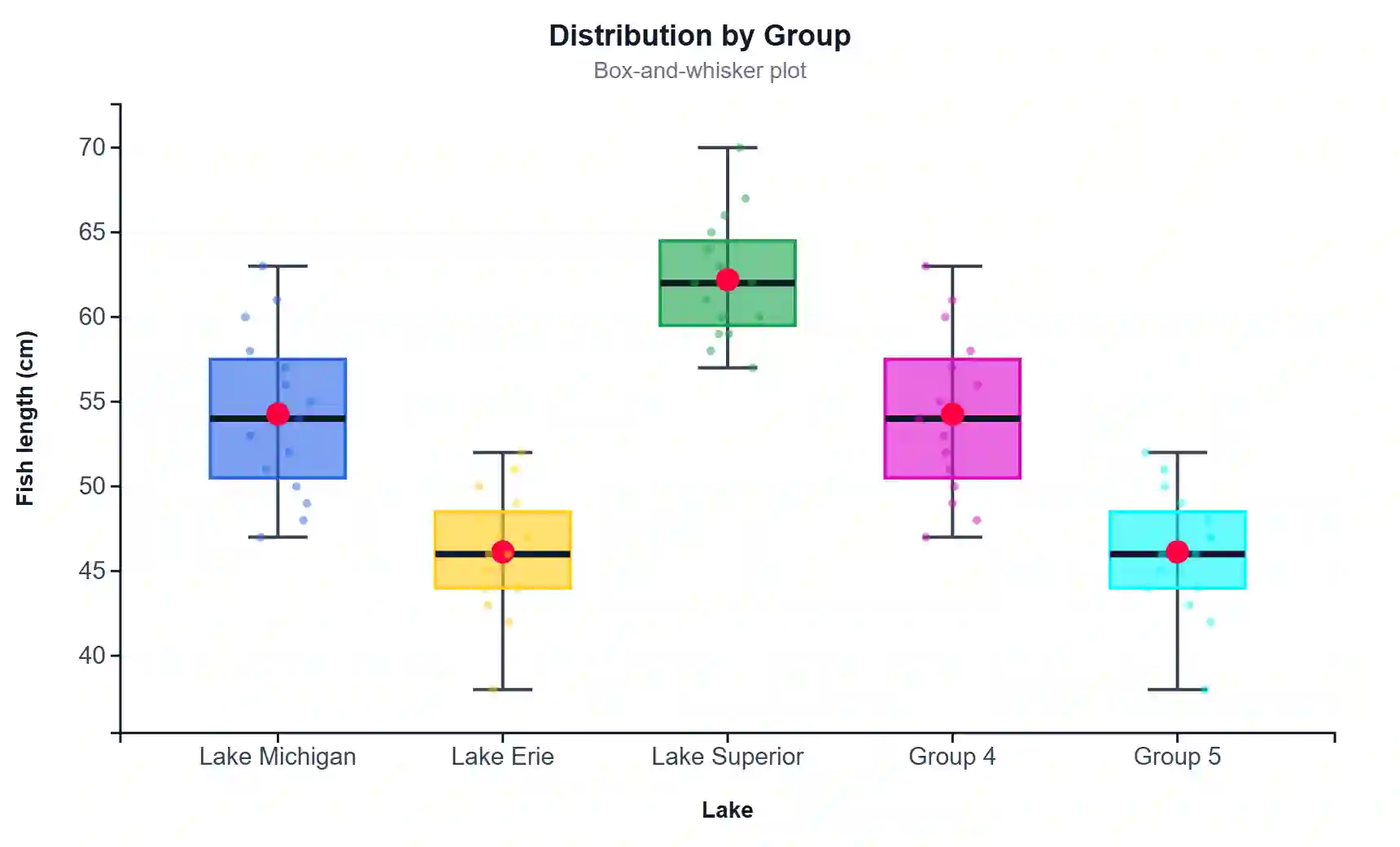
① Box Plot — Group Distributions
② Violin / Density Plot — Data Spread
③ Mean ± SD Bar Chart with Error Bars
④ t-Distribution with Critical Region
Use one of the five templates below. Each template is auto-filled with your exact computed values. Click 📋 Copy to copy to clipboard.
🧮 Technical Notes — Formulas Used
📌 When to Use the Independent Samples t-Test
Use the independent samples t-test when ALL of the following conditions are met:
Quick Comparison: Which Test Should I Use?
| Situation | Recommended Test |
|---|---|
| Two independent groups, continuous data, normal or large n | ✓ Independent t-Test (this tool) |
| Two independent groups, non-normal & small n (< 30) | Mann-Whitney U Test |
| Two related groups (before/after, matched pairs) | Paired Samples t-Test |
| Three or more independent groups | One-Way ANOVA |
| Two independent groups, binary outcome | Chi-Square / Fisher's Exact |
| One group vs. a known population value | One-Sample t-Test |
Decision Tree: Welch's vs Student's t-Test
(Variances equal)
(df = n₁+n₂−2)
(Variances unequal)
(Satterthwaite df)
Real-World Examples
- Comparing mean blood pressure between a drug group and a placebo group
- Testing whether male and female students score differently on a standardised test
- Measuring whether a new teaching method improves exam scores vs. traditional teaching
- Comparing body mass index (BMI) between urban and rural populations
- Assessing whether two factory production lines differ in average output per hour
📖 How to Use This Calculator — Step-by-Step Guide
Use the Paste/Type tab for quick comma-separated entry (e.g., 52, 48, 55, 61 ...). Use Upload File for CSV or Excel data. Use Manual Entry to type values one by one.
Click the editable group name fields and type meaningful labels (e.g., "Treatment" and "Control"). These appear in the results and write-up templates.
Use the dropdown to load one of five built-in sample datasets. This helps you see what results look like before entering your own data.
Select α (significance level), test direction (two-tailed or one-tailed), and t-test variant. Use "Auto" to let Levene's test decide between Welch's and Student's.
The calculator runs automatically. Results, charts, and interpretation appear below the input section.
The colored badge (Significant / Not Significant) gives the immediate verdict. The stats grid shows t, p, df, and Cohen's d at a glance.
Box plot shows medians and spread. Violin plot shows the data distribution shape. Bar chart shows means ± SD. The t-distribution plot shows your test statistic versus the critical region.
The tool automatically checks normality (Shapiro-Wilk) and variance equality (Levene's). Follow the guidance if any assumption is violated.
Paragraphs explain your p-value, effect size, CI, and practical significance in plain English — ready to use in a discussion or report.
Choose from APA 7th, Thesis/Dissertation, Plain Language, Abstract/Poster, or Pre-registration format. All values are auto-filled. Hit Copy and paste into your paper.
What is an independent samples t-test?
What is the difference between Welch's t-test and Student's t-test?
What does the p-value mean in a t-test?
What is Cohen's d and how is it interpreted?
What are the assumptions of the independent samples t-test?
How do I choose between one-tailed and two-tailed t-test?
What sample size do I need for an independent samples t-test?
What should I do if my data violates normality?
How do I report an independent samples t-test in APA format?
Can I upload Excel or CSV files to this calculator?
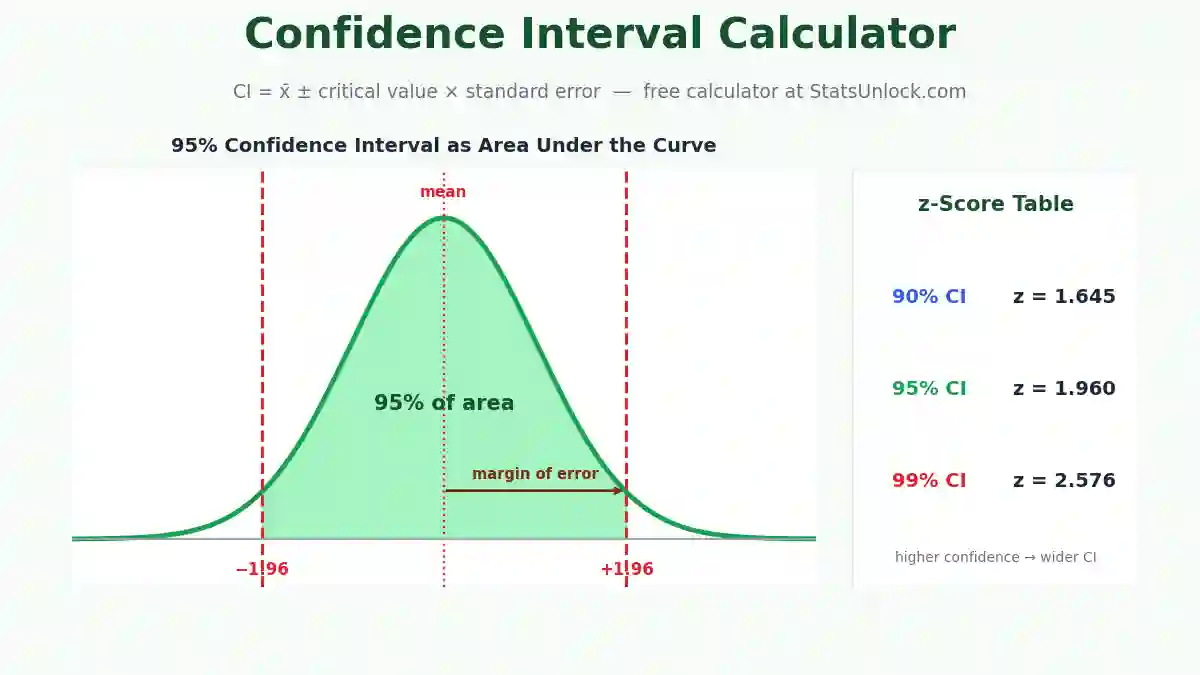
What is the confidence interval in a t-test, and what does it mean?
What is Levene's test and when should I use Welch's instead of Student's?
The independent samples t-test calculator on StatsUnlock follows the statistical methodology for two-group mean comparison, effect size estimation, and assumption checking described in the following peer-reviewed sources on independent t-test analysis and applied statistics.
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates. https://doi.org/10.4324/9780203771587
- Welch, B. L. (1947). The generalization of "Student's" problem when several different population variances are involved. Biometrika, 34(1–2), 28–35. https://doi.org/10.1093/biomet/34.1-2.28
- Student [W. S. Gosset]. (1908). The probable error of a mean. Biometrika, 6(1), 1–25. https://doi.org/10.1093/biomet/6.1.1
- Levene, H. (1960). Robust tests for equality of variances. In I. Olkin et al. (Eds.), Contributions to probability and statistics (pp. 278–292). Stanford University Press.
- Shapiro, S. S., & Wilk, M. B. (1965). An analysis of variance test for normality (complete samples). Biometrika, 52(3–4), 591–611. https://doi.org/10.1093/biomet/52.3-4.591
- Moser, B. K., & Stevens, G. R. (1992). Homogeneity of variance in the two-sample means test. The American Statistician, 46(1), 19–21. https://doi.org/10.1080/00031305.1992.10475845
- Delacre, M., Lakens, D., & Leys, C. (2017). Why psychologists should by default use Welch's t-test instead of Student's t-test. International Review of Social Psychology, 30(1), 92–101. https://doi.org/10.5334/irsp.82
- Hedges, L. V., & Olkin, I. (1985). Statistical methods for meta-analysis. Academic Press. https://doi.org/10.1016/C2009-0-03396-0
- Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: A practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4, 863. https://doi.org/10.3389/fpsyg.2013.00863
- Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
- Cumming, G. (2014). The new statistics: Why and how. Psychological Science, 25(1), 7–29. https://doi.org/10.1177/0956797613504966
- Sullivan, G. M., & Feinn, R. (2012). Using effect size — or why the p value is not enough. Journal of Graduate Medical Education, 4(3), 279–282. https://doi.org/10.4300/JGME-D-12-00156.1
- Satterthwaite, F. E. (1946). An approximate distribution of estimates of variance components. Biometrics Bulletin, 2(6), 110–114. https://doi.org/10.2307/3002019
- Royston, P. (1992). Approximating the Shapiro-Wilk W-test for non-normality. Statistics and Computing, 2(3), 117–119. https://doi.org/10.1007/BF01891203
- American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). APA. https://doi.org/10.1037/0000165-000