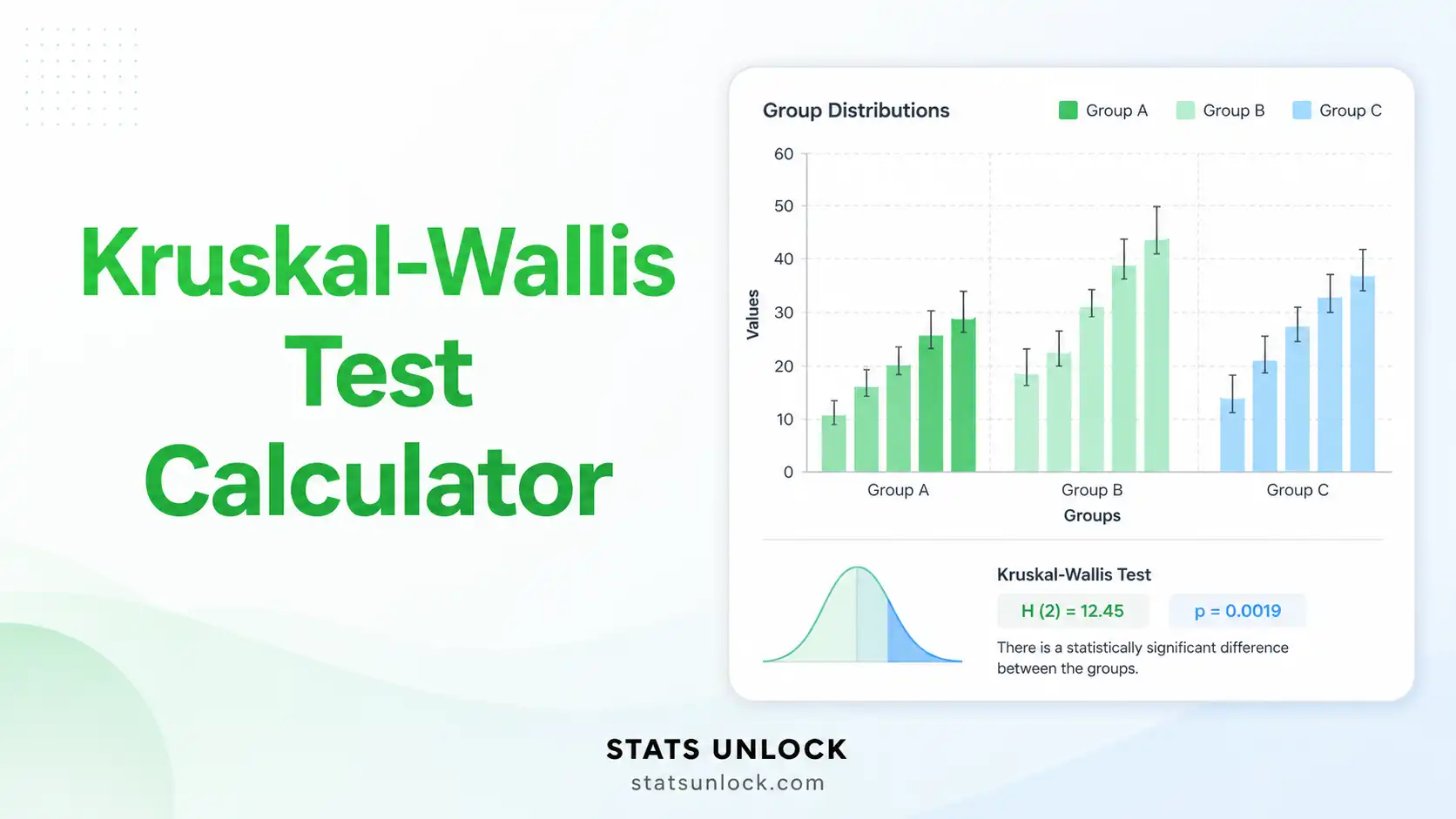
Kruskal-Wallis Test Calculator
Free online H-test calculator — compare three or more independent groups without normality. Includes Dunn's post-hoc test, effect size (η²), APA write-ups, and four interactive visualizations.
Last updated: June 2025 · Author: Reegan Puspanathan, Wildlife Biologist & Data Analyst
Choose the writing style that matches your output — dissertation, journal article, plain-language summary, conference poster, or pre-registration. All templates are auto-filled with your computed statistics.
Type or paste comma-separated values for each group, upload a CSV/Excel file, or use the manual entry table. Each group represents one category of your independent variable.
Click the editable group name box above each textarea (e.g., "Control", "Low Dose", "High Dose") to label your groups meaningfully. Names appear in all outputs.
Use the "+ Add Group" and "− Remove Last Group" buttons. You can compare 3 to 6 groups. The test requires at least 3 groups; for 2 groups, use the Mann-Whitney U test instead.
Select one of the 5 built-in sample datasets from the dropdown to explore how the tool works before entering your own data. Each sample represents a real-world research scenario.
Choose 0.01, 0.05, or 0.10. The most common choice in academic research is α = 0.05, meaning a 5% probability threshold for declaring a result significant.
Holm-Bonferroni is recommended as it controls family-wise error while being more powerful than standard Bonferroni. Select "None" to see raw p-values without adjustment.
Click "Run Kruskal-Wallis Test". Results appear immediately — H-statistic, degrees of freedom, p-value, effect size (η²), and group summary statistics including median and mean rank.
The box plot shows medians and IQR. The rank chart compares mean ranks per group. The KDE violin plot shows distribution shape. The scatter plot shows individual ranked observations.
Read the detailed interpretation section. It tells you whether differences are statistically significant, explains the effect size in practical terms, and highlights which pairs differ post-hoc.
Click "📋 Copy" on any write-up card (APA, Thesis, Plain Language, Abstract, Pre-Registration) to copy a fully auto-filled results paragraph for your paper or report.
✅ Use Kruskal-Wallis When…
- You have 3 or more independent groups
- Your data violates normality (skewed, ordinal)
- Group sizes are small (n < 20 per group)
- Your dependent variable is ordinal
- Significant outliers are present in the data
- You are comparing ranks rather than means
❌ Avoid Kruskal-Wallis When…
- Data is normally distributed (use one-way ANOVA)
- Groups are related / paired (use Friedman test)
- You have only 2 groups (use Mann-Whitney U)
- Your dependent variable is binary (use chi-square)
- You need to include covariates (use ANCOVA)
- • Ecology: Comparing species richness across three habitat types (forest, grassland, wetland)
- • Clinical: Comparing pain scores (0–10 ordinal scale) across four treatment arms
- • Education: Comparing test performance across five teaching methods with non-normal score distribution
- • Biology: Comparing plant growth across three fertilizer types when data is right-skewed
The Kruskal-Wallis test calculator on this page is based on the original rank-sum methodology for non-parametric one-way ANOVA, Dunn's pairwise post-hoc comparisons, and eta-squared effect size estimation. Key peer-reviewed sources are listed below.









