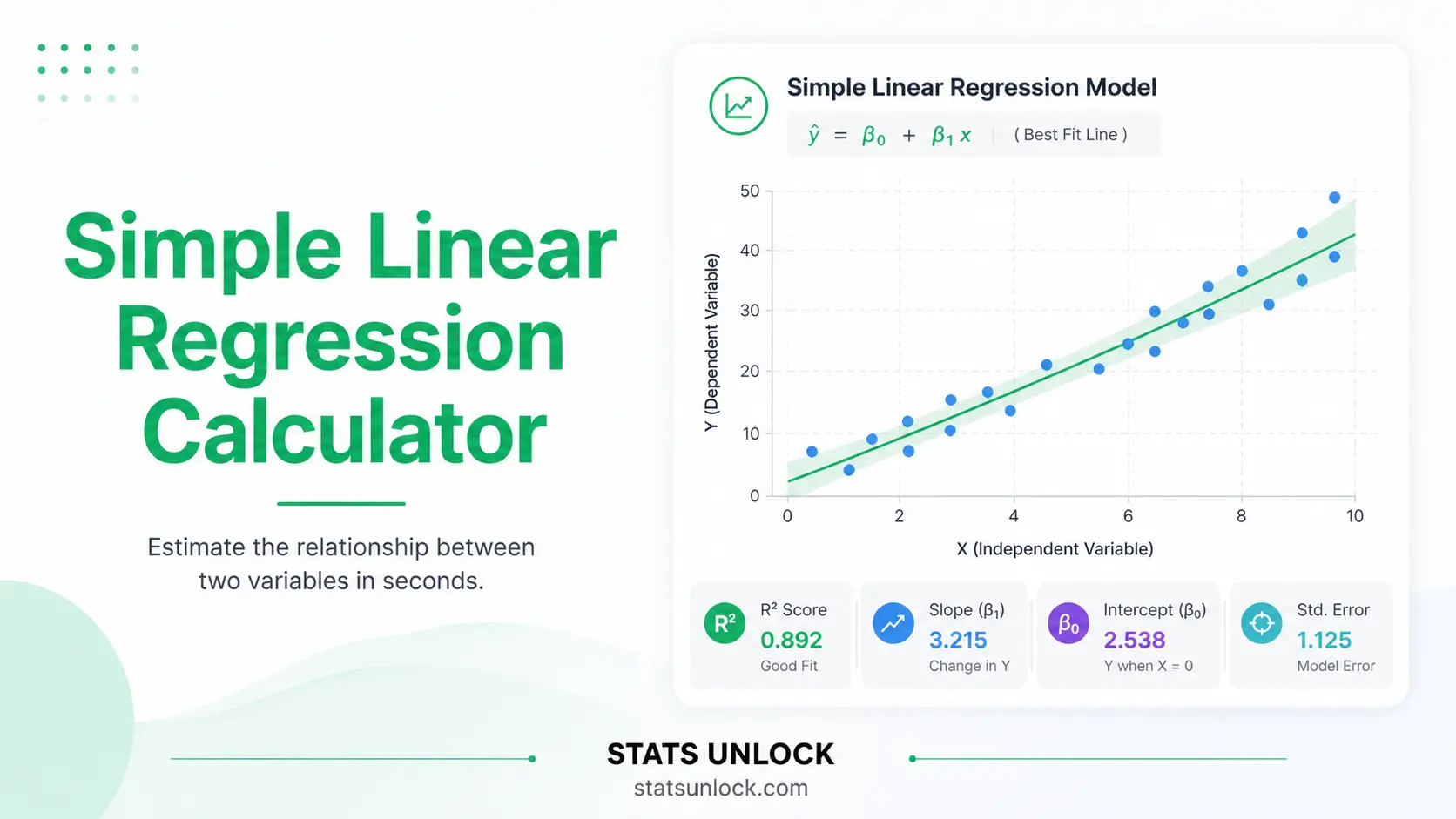
Simple Linear
Regression Calculator
Free online OLS tool that fits Y = b₀ + b₁X, computes slope, intercept, R², adjusted R², F-statistic, p-value, 95% confidence intervals, residual plots and APA-format results in one click.
1. Enter Your Data
| X (predictor) | Y (outcome) |
|---|
2. Results Summary
| Statistic | Value | Description |
|---|
📊 ANOVA Summary Table
Decomposition of total variance in Y into regression and residual components — used to test overall model significance.
| Source | SS | df | MS | F | p-value |
|---|
📋 Data Table — Observed, Predicted & Residuals
Per-observation breakdown showing each X-Y pair, the predicted Ŷ from the regression line, the raw residual (Y − Ŷ), and the standardised residual (|z| > 2 flagged in amber as a possible outlier).
| # | X | Y | Ŷ (Predicted) | Residual (Y − Ŷ) | Std. Residual |
|---|
3. Colorful Visualizations
4. Detailed Interpretation of Results
5. How to Write Your Results in Research
Five ready-to-use simple linear regression reporting templates — APA, thesis, plain-language, conference abstract and pre-registration. Click 📋 Copy to grab the auto-filled paragraph.
6. Detailed Conclusion
📐 Technical Notes & Formulas Used
Sub-section A — Formulas
Sub-section B — Technical Notes
🎯 When to Use Simple Linear Regression
This free simple linear regression calculator is designed for researchers, students and analysts who need to estimate the linear relationship between one continuous predictor (X) and one continuous outcome (Y), test whether that relationship is statistically significant, and produce publication-ready results in seconds.
Decision Checklist
- You have one predictor (X) and one outcome (Y), both continuous.
- The relationship between X and Y is approximately linear (check the scatter plot).
- Observations are independent of one another.
- Residuals are approximately normally distributed (check the Q-Q plot).
- Residual variance is roughly constant across X (homoscedasticity — check residuals-vs-fitted).
- Do not use if you have two or more predictors → use multiple linear regression.
- Do not use if Y is binary or count data → use logistic or Poisson regression.
- Do not use if the relationship is clearly curved → consider polynomial regression or transformation.
- Do not use with strong outliers without first investigating them.
Real-World Examples
- Education — Predict exam score from hours studied per week.
- Marketing — Predict monthly sales from advertising spend.
- Ecology — Predict tree height from trunk diameter at breast height (DBH).
- Agriculture — Predict crop yield from fertilizer dose.
- Public health — Predict body-mass index from daily caloric intake.
Sample Size Guidance
- Absolute minimum: n = 10 paired observations (results unstable below this).
- Recommended for moderate effects: n ≥ 30.
- For 80% power to detect a medium effect (R² ≈ 0.13) at α = .05: n ≈ 55.
- For 80% power at small effect (R² ≈ 0.02): n ≈ 395.
Related Tests — Decision Tree
🛠️ How to Use This Simple Linear Regression Calculator
- Pick a sample dataset from the dropdown to see how the tool works, or skip to step 2 with your own data.
- Edit the dataset / group name field — this label appears in your downloaded report and APA writeup.
- Enter X values (predictor) in the first textarea, comma-separated. Example:
1, 2, 3, 4, 5. - Enter Y values (outcome) in the second textarea, comma-separated. The number of values must match X exactly.
- Or upload a file: switch to the Upload tab, choose a .csv / .txt / .xlsx file, and assign which column is X and which is Y.
- Or use Manual Entry: switch to the Manual tab, type values into the spreadsheet-like grid, then click "Use Manual Data".
- Choose alpha (default 0.05). This sets the significance threshold and the confidence-interval width.
- Click "Run Simple Linear Regression". Results, charts, interpretation and APA-format writeups appear instantly.
- Inspect the diagnostic plots (residuals, Q-Q, histogram) to verify regression assumptions before reporting.
- Download the report as a .txt file or print/save as PDF for your thesis, paper or class assignment.
❓ Frequently Asked Questions (FAQ)
What is simple linear regression and when should I use it?
Simple linear regression models the straight-line relationship between one continuous predictor (X) and one continuous outcome (Y). Use it when you want to estimate how much Y changes for each one-unit change in X, predict Y from a known X value, or test whether the linear association between two variables is statistically different from zero. A common example is predicting exam score from study hours.
What is R-squared in simple linear regression?
R-squared (R²) is the proportion of variance in the outcome (Y) that is explained by the predictor (X). It ranges from 0 to 1. An R² of 0.75 means X explains 75% of the variability in Y. Higher values mean a tighter fit, but R² alone is not enough — always inspect the residual plots before trusting it. R² is also equal to the squared Pearson correlation between X and Y in simple linear regression.
How do I interpret the slope (b₁) in simple linear regression?
The slope tells you the predicted change in Y for every one-unit increase in X. If the slope is 2.5, then on average Y increases by 2.5 units when X increases by 1 unit. A negative slope means Y decreases as X increases. The 95% confidence interval for the slope tells you the range of plausible values for this true effect in the population.
What does the p-value mean in simple linear regression?
The p-value tests whether the slope is significantly different from zero. If p < 0.05, you reject the null hypothesis of no linear relationship. A p-value of 0.03 means there is a 3% probability of seeing a slope this large by chance alone if there were truly no relationship. The p-value does not tell you the size of the effect — always report the slope, confidence interval and R² alongside it.
What assumptions does simple linear regression require?
Five assumptions: (1) linearity between X and Y; (2) independence of residuals; (3) homoscedasticity (constant residual variance); (4) normally distributed residuals; (5) no extreme outliers or high-influence points. The diagnostic plots in this tool — residuals-vs-fitted, Q-Q plot and histogram of residuals — let you check assumptions 1, 3, and 4 visually. If assumptions are badly violated, consider transforming Y, fitting a robust regression, or using a different model entirely.
How large a sample do I need for simple linear regression?
A practical rule of thumb is 20–30 paired observations as a minimum, with 50+ preferred for stable estimates. For 80% power to detect a medium effect (R² ≈ 0.13) at α = 0.05, you need approximately n = 55. Very small samples (n < 10) produce unreliable slopes, wide confidence intervals and unstable p-values, even when the true effect is real.
What is the difference between correlation and simple linear regression?
Pearson correlation (r) measures the strength and direction of a linear association between two variables, but does not give you a prediction equation. Simple linear regression goes further: it estimates the slope and intercept of the best-fit line, allowing you to predict Y from X and to express the relationship in real-world units. Mathematically, R² in simple linear regression equals the squared Pearson correlation (r²).
How do I report simple linear regression results in APA 7th edition format?
A standard APA 7 sentence: "A simple linear regression was conducted to predict Y from X. The model was statistically significant, F(1, 28) = 35.21, p < .001, R² = .56. The slope was b = 2.43, 95% CI [1.62, 3.24], t(28) = 5.93, p < .001." Always italicize statistical symbols. See Section 5 of this page for five reporting templates with one-click copy buttons.
Can I use this calculator for my published research or thesis?
Yes — for education, exploratory analysis, classroom assignments and replication checks. For a peer-reviewed publication, verify the results against R, Python, SPSS or SAS as a cross-check. Cite the tool as: STATS UNLOCK. (2025). Simple linear regression calculator. Retrieved from https://statsunlock.com.
What should I do if my regression results are non-significant?
A non-significant result (p > α) does not prove that X has no effect on Y — it only means the data do not provide sufficient evidence to reject the null hypothesis. Possible reasons: low statistical power, small sample size, measurement noise, non-linear relationship, or a genuinely small (or zero) effect. Run a power analysis, check the scatter plot for non-linear patterns, and consider whether a larger or better-measured sample might detect a real but small effect.
📚 References
The following references support the statistical methods used in this simple linear regression calculator, covering OLS estimation, p-value interpretation, effect size reporting, and best practices in hypothesis testing for bivariate regression.
- Galton, F. (1886). Regression towards mediocrity in hereditary stature. The Journal of the Anthropological Institute of Great Britain and Ireland, 15, 246–263. https://doi.org/10.2307/2841583
- Pearson, K. (1896). Mathematical contributions to the theory of evolution. III. Regression, heredity, and panmixia. Philosophical Transactions of the Royal Society of London A, 187, 253–318. https://doi.org/10.1098/rsta.1896.0007
- Fisher, R. A. (1925). Statistical methods for research workers. Oliver and Boyd.
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
- Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th ed.). SAGE Publications.
- Fox, J. (2016). Applied regression analysis and generalized linear models (3rd ed.). SAGE Publications.
- Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press. https://doi.org/10.1017/CBO9780511790942
- Kutner, M. H., Nachtsheim, C. J., Neter, J., & Li, W. (2005). Applied linear statistical models (5th ed.). McGraw-Hill/Irwin.
- Cumming, G. (2014). The new statistics: Why and how. Psychological Science, 25(1), 7–29. https://doi.org/10.1177/0956797613504966
- Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science. Frontiers in Psychology, 4, 863. https://doi.org/10.3389/fpsyg.2013.00863
- American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). APA. https://doi.org/10.1037/0000165-000
- R Core Team. (2024). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
- NIST/SEMATECH. (2013). e-Handbook of statistical methods. National Institute of Standards and Technology. https://www.itl.nist.gov/div898/handbook/
- Seabold, S., & Perktold, J. (2010). statsmodels: Econometric and statistical modeling with Python. Proceedings of the 9th Python in Science Conference, 92–96.









